 Science Explorer
Science Explorer
SciX Models and Datasets
Thomas Allen (ADS Backend Developer)
23 Oct 2023
Introduction
The Astrophysics Data System (ADS) has been developing Natural Language Processing tools and datasets to further enhance its data holdings and services. As part of this effort, we have been building and curating datasets to train deep learning models. These new tools, and more that will build upon them, will both provide a richer user experience and allow internal processes to be scaled-up. Further, we expect that these tools will be useful to researchers in a variety of fields. This post will describe our models and datasets for interested researchers. We are strong proponents of open science, and we endeavor to make our datasets publicly available and easy to access. This post contains links to our curated datasets and will be updated as more datasets are created. The models are licensed under an MIT license and the datasets are licensed under a CC-BY 4.0 license. Briefly, these licenses allow researchers to use, share, modify or build upon these works as long as appropriate attribution is given. If there are any questions about fair usage, contact us at ADS help.
astroBERT
To support broad community participation in these efforts, we have recently released the astroBERT astrophysics-specific language model. A language model is a statistical representation of the relationships among words, and even sub-word units called tokens, in a corpus of text. By creating a model that is astronomy specific, we can better account for the nuances of the language used in the astrophysical literature.
astroBERT is built using a proven deep learning architecture. Specifically it is an encoder based transformer model (these blogs discuss transformer models and their variations) that was trained on ~400k astrophysics articles (3.8 billion tokens). The training took about 50 days on dual Nvidia V100 GPUs. All technologies used to build the model are open source.
astroBERT was trained using Masked Language Model (MLM) and Next Sentence Prediction (NSP) tasks. For the MLM tasks, a word within a sentence is removed, and the model tries to predict what that word is. For example: The [MASK] medium is the gas and dust between stars. For the NSP task, two sentences are presented and the model tries to determine if the second sentence follows the first. Publicly available versions of astroBERT include:
- Base astroBERT - version trained using MLM + NSP
- NER-DEAL - fine-tuned version of astroBert for NER task
- SciX Categorizer - fine-tuned version of astroBERT for classification task
Further technical details about astroBERT can be found in the following paper. The astroBERT page on Hugging Face includes documentation about how to access and utilize the model, as well as all publicly available versions.
Detecting Entities in the Astrophysical Literature (DEAL)
The Detecting Entities in the Astrophysical Literature (DEAL) dataset is a curated dataset for Named Entity Recognition. This task involves identifying predetermined entities in text, such as Organization or Location. The dataset consists of text fragments obtained from the astrophysical literature. The journals that the text fragments were obtained from are the Astrophysical Journal, Astronomy & Astrophysics, and the Monthly Notices of the Royal Astronomical Society. All text fragments are from recent publications, between the years of 2015 and 2021. Each text fragment is roughly a paragraph in length, and originates from one of two parts of an article. The first are fragments from the fulltext, consisting of all sections of the body of the article, excluding the abstract and acknowledgments sections. The second are fragments from the acknowledgments section of the article. Roughly 6000 text snippets were labeled, containing over 147,000 labeled entities. Figure 1 shows an example of a manually labeled text snippet.

Figure 1: Example of a manually labeled full text snippet.
Thirty-three different entities, composed of general and astrophysical entities, were manually labeled in each text fragment by a domain expert. The entities that were labeled cover a number of broad categories. One category contains common NER entities, such as Person, Organization, and Location. A second category contains entities related to astrophysical facilities, such as Observatory, Telescope and Instrument. A third category contains entities related to research funding and proposals, such as Grant or Proposal. A fourth category contains entities relating to astronomical objects and regions of the sky. Finally there is a category that contains various entities that are found in the literature, such as URLs and citations. A full list of the named entities with examples can be found here. Figure 2 shows the counts for the categories of entities, color coded by source with the full text in blue and acknowledgments in red. It is worth noting two points about this distribution. First, the categories are highly unbalanced, with some categories having orders of magnitude more counts than others. Second, the distribution of categories is different for the full text and the acknowledgements.
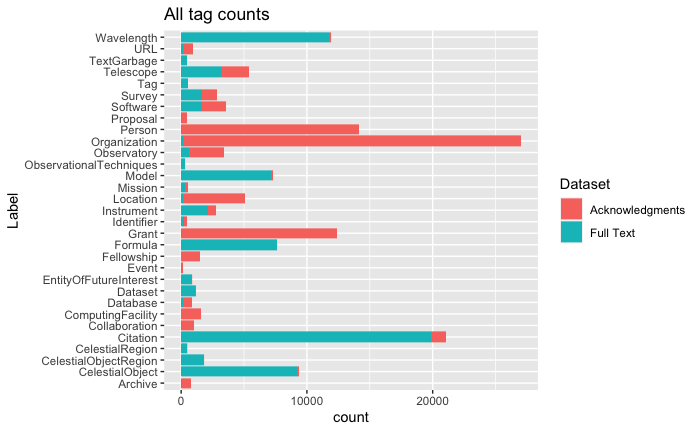
Figure 2: Counts of labeled entities. Red denotes entities labeled in the Acknowledgments section of a paper, and blue denotes entities labeled in the body of a paper.
The DEAL dataset was used as part of a shared task in the First Workshop on Information Extraction from the Scientific Literature (WIESP 2022) as part of the AACL-IJCNLP 2022 conference. The proceedings of this workshop are part of the ACL Anthology.
Function Of Citation in Astrophysics Literature (FOCAL)
The Function Of Citation in Astrophysics Literature (FOCAL) dataset is a curated dataset for citation context analysis. Citation context analysis “facilitates the syntactic and semantic analysis of the contents of the citation context to understand how and why authors discuss others research work” (Kunnath et al. 2021). Citation context analysis includes the determination of citation function, or the reason an author is including a particular citation; citation polarity, or the author’s sentiment towards the cited work, either positive or negative; and citation impact, or the importance of a cited work to the citing work.
We are considering a set of eight potential citation functions. These are:
- Background: The cited work provides background information needed to understand the citing work
- Motivation: The cited work is motivating the citing work
- Uses: The citing work used a result from the cited work
- Extends: The citing work extends a result from the cited work.
- Similarities: Results from the cited work are similar to results from the citing (or another) work.
- Differences: Results from the cited work are different to results from the citing (or another) work.
- Compare/Contrast: Results are being compared in a neutral manner between the cited and he citing (or another) work.
- Future Work: Citing work contains implications for future research that are often beyond the scope of the citing work.
| Function | Count |
|---|---|
| Background | 2435 |
| Uses | 1637 |
| Compare/Contrast | 933 |
| Similarities | 401 |
| Motivations | 359 |
| Diferences | 189 |
| Future Work | 53 |
| Extends | 16 |
| Total | 6023 |
Table 1: Counts for each citation function category in the FOCAL dataset.
The snippets that contain the citations are obtained from over 25,000 astronomy articles, from the same journals and publication years as the DEAL dataset. From this set of articles, over 2 million citations and their context are harvested. Further, only citations with context sizes between 2,000 and 10,000 characters are selected. This is to allow the determination of what portions of the context are most relevant to understanding the citation’s function. A domain area expert manually examined these text snippets to determine the citation function as well as label the relevant context. In total there are 6023 instances of annotated citations. Table 1 shows the number of instances for each citation function category.

Figure 3: An example of a manually labeled citation context text snippet.
There are a number of open questions in citation context analysis research that we hope this dataset will help address. These include determining what the necessary text is to understand a citation’s function, as well as addressing multiple functions for a given cited work. Figure 3 shows an example of a manually labeled citation context. In this example the same work is cited a number of times within the text snippet, and these citation instances serve different functions.
The FOCAL dataset will be used for the Second Workshop on Information Extraction from the Scientific Literature (WIESP 2023) part of IJCNLP-AACL 2023.
We Want to Hear From You
If you find any of these datasets useful in your research or if you are working on similar efforts, we would like to hear from you. You can contact the ADS Team at ADS help.
Linked Resources
astroBERT model: https://huggingface.co/adsabs/astroBERT
astroBERT paper: https://arxiv.org/abs/2112.00590
WEISP 2022 Workshop: https://ui.adsabs.harvard.edu/WIESP/2022/
WEISP Proceedings: https://aclanthology.org/volumes/2022.wiesp-1/
DEAL Dataset: https://huggingface.co/datasets/adsabs/WIESP2022-NER
FOCAL Dataset https://huggingface.co/datasets/adsabs/FOCAL
Questions or feedback? Contact us at help@scixplorer.org.