ADS Indexes Its 100,000,000th Citation
Kelly Lockhart (ADS Developer)
05 Oct 2017
108 Citations and Counting!
The ADS has reached its 100,000,000th citation! We hit this milestone the last week of September during our daily paper ingest. The 108 citation occurred during a batch ingest of papers that generated over a million citations. The most highly cited paper that received a citation in this ingest (and thus the unofficial winner of the 108 citation prize) is “Planck 2015 results. XIII. Cosmological parameters.” The citing paper is “Constraining the mass of light bosonic dark matter using SDSS Lyman-α forests.”
Our citations database has doubled in roughly the last 6 years. The growth in citations is rapid: the number of citations in the database increased nearly five-fold in the last decade and by two orders of magnitude in the last two decades.
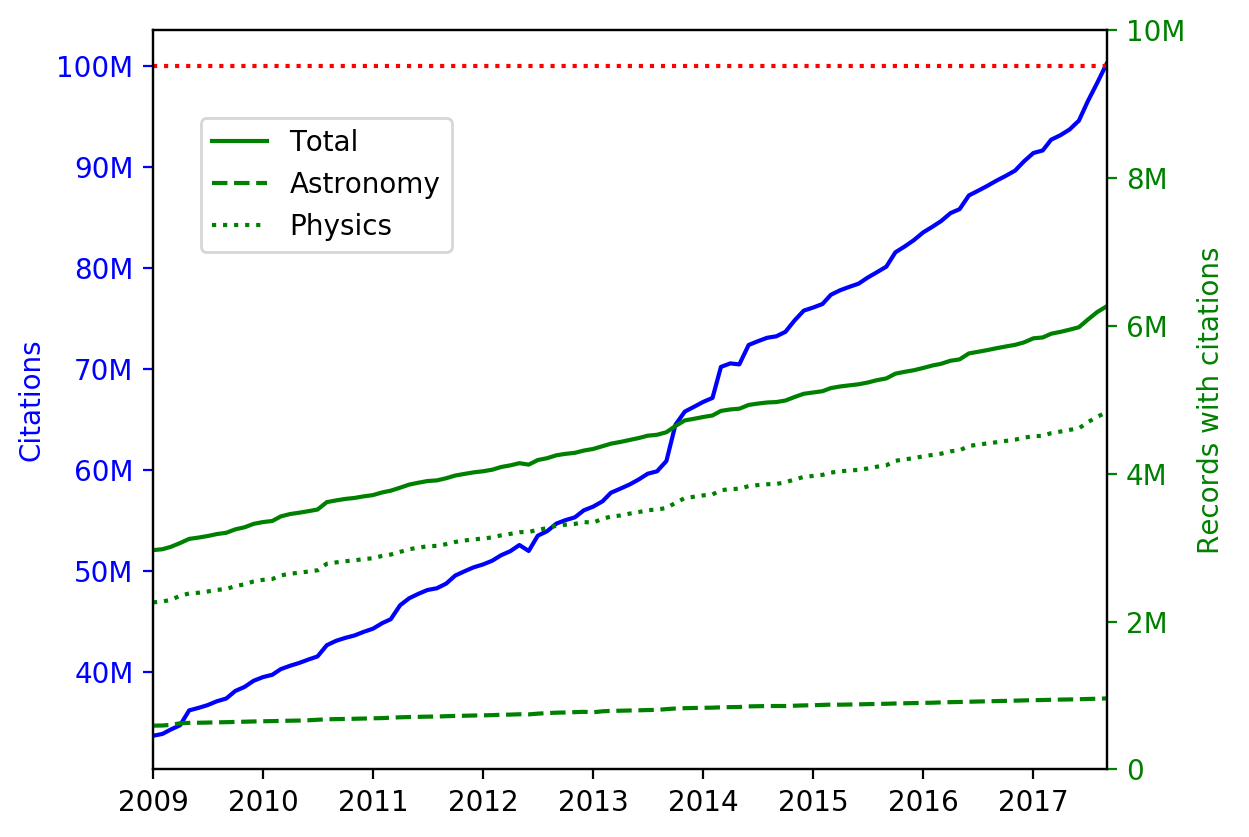
The number of records in the database that have been cited at least once has also increased over the same timespan, though not as quickly as the number of citations. The number of records in physics and astronomy that have been cited at least once has nearly doubled in the last 8 years. The more rapid increase in the number of citations than in the number of papers being cited is more easily visualized by the figure below, and is best understood when thinking of the citation dataset as a network of papers connected by citations. The figure, originally published as figure 4 in “The ADS in the Information Age - Impact on Discovery” and using data from 1980–2006, shows the number of edges (or number of citations) as a function of the number of nodes (or records that have been cited). The nonlinear growth of the number of citations is evidence of network densification.
 vs. records (nodes), for the period from 1980 to 2006")
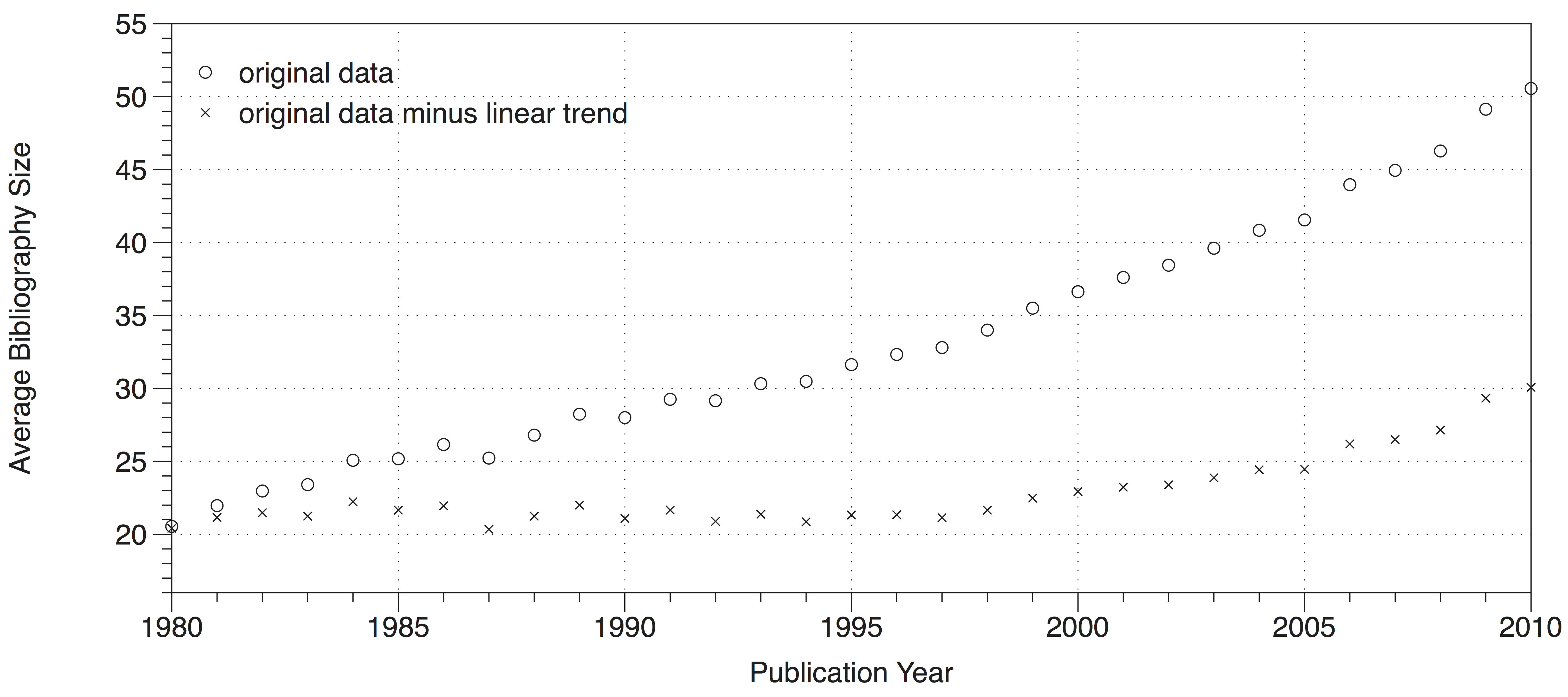
This is partly a consequence of the growth in the average number of references in a bibliography, seen in the figure below (originally figure 5 from the same publication). This trend has only increased since widespread adoption of electronic publishing in the late 1990s, seen as the upwards deviation from the linear trend in bibliography growth.
The process by which a paper is cited in the ADS is not always obvious to our users. When a paper is ingested, the publisher-provided reference list is read. (For arXiv e-prints or other works without separate reference lists, the paper’s full text is scanned and references are extracted directly from the text.) Individual reference strings are recognized and the bibliographic tokens within them are parsed. We then attempt to match the parsed reference metadata against the existing records within ADS. When a possible match is found, we compute a similarity score between the parsed reference data and that of the potential match in ADS. If the similarity score is high enough, the reference is accepted and a reference/citation pair is created between the referencing paper and the cited paper. The citations table is formed by inverting the references table. The resulting citations table is then checked for duplicates, such as from previous versions of the citing paper that have appeared on the arXiv.
Papers will be properly cited in ADS if and only if the following conditions are met: the citing paper is in ADS, ADS has access to the full text (or at least the references section) of the citing paper, the reference to the cited paper is properly parsed and identified (which requires that the references are in a recognizable format), and the cited paper is in ADS. It is this process that has produced over 100 million citations to date! With all the steps involved, it is possible that our system will miss a citation here and there, despite our best efforts at curating the database. We rely on our users’ feedback to continuously improve our citation coverage and welcome your input, so if you see something wrong, please let us know!
Questions or feedback? Contact us at adshelp@cfa.harvard.edu.