What's New
This page is updated monthly with a list of new ([new]) and improved ([improved]) features and bug fixes ([fixed]) to our website, API, data pipelines, and data holdings. We also list operations issues and improvements of note ([ops]).
To receive this listing via monthly email newsletter, along with announcements and new blog posts, sign up here.
July 2026
Announcements:
 Chat with us at EAS today!
Chat with us at EAS today!ADS/SciX team members Alberto Accomazzi (ADS PI), Kelly Lockhart (ADS Tech Lead), and Sergi Blanco Cuaresma (ADS Research Associate) are staffing the SciX exhibit booth at the European Astronomical Society Annual Meeting taking place June 28-July 3 in Lausanne, Switzerland. Visit booth #17 to learn more about the transition from ADS to SciX taking place this fall and explore further the SciX platform. Most importantly, help yourself to a range of new SciX logo items fresh off the press. Whether you're a longtime user or just learning about SciX, we'd love to meet you and hear about your research needs.
Alberto Accomazzi is also participating in Special Session 44, “AI and Open Access in modern astronomy publishing” which takes place on Friday, July 3rd. He will be a panelist in block 1 (“Astronomy Publishing Today”) and a speaker in block 2 (“AI in Astronomy Publishing and its Practical Applications”), providing an ADS perspective on the use of AI to support astronomy research. We hope to see you there!
The ADS and SciX teams will be at the 46th COSPAR Scientific Assembly in Florence, taking place August 1-9, 2026. The assembly will bring together thousands of scientists, engineers, and space agency representatives for over 150 scientific sessions dedicated to sharing the latest advancements in space exploration, planetary science, and climate monitoring. ADS/SciX team members Alberto Accomazzi and Daniel Chivvis will be staffing the SciX booth for the duration of the meeting and Alberto will give a solicited talk about SciX in the Fair Infrastructure and Open Science Session on Wednesday, August 5th.

Project scientist for astrophysics Jennifer Lynn Bartlett (2nd from left), accompanied (Harlow Shapley Project; 2nd from right) to Gabriele Vajente’s (LIGO; right) “Talks + Telescopes” presentation about Gravitational Waves at Mt. Wilson on June 20. Sam Hale (left), grandson of George Ellery Hale, is president of the Mount Wilson Institute, which took over management of the facility from the Carnegie Institute of Washington in 1989. Deborah is the granddaughter of Martha and Harlow Shapley. Harlow worked at Mt. Wilson from 1914 until 1921. During this period, Martha gave birth to their first three children and published her first 14 astronomical papers, including four first-author papers in the Astrophysical Journal or Publications of the Astronomical Society of the Pacific. Bartlett is helping Deborah prepare a biography of Martha Shapley.
Development and data holdings updates as of July 1st:
- Website and API Releases
- [new] Added AI policy to help page
- [improved] Updated and reformatted the bibgroups page for readability
- Data holdings and pipelines
- 168k new records, and 12.9M new citations
- 50K theses from SISSA, MIT, Caltech, Rice, UChicago newly indexed
Development details
- Journals Database Releases
- v1.3.10 - [improved] Modified the table that tracks the history of journals to identify predecessor and successor journals by ISSN and coden in addition to bibstem
- Nectar Releases
- v0.48.5 - [improved] Set icon button size
- Solr Releases
- v96.5.2 - [ops] Improved performance from query memory allocation
- Solr-Service Releases
- v1.1.7 - [ops] Add logging for allocation data provided by Solr
- [fixed] Bug affecting list components in Feedback Forms
- [fixed] Make mention and mention_count optional
- [fixed] Prevent reverting user format change when navigating to Export Formats
- [ops] Auto-populate int/float fields so that new fields are automatically recognized
June 2026
Announcements:
SciX is excited to exhibit at the European Astronomical Society Annual Meeting 2026, June 28-July 3 in Lausanne, Switzerland. Visit our booth to explore the SciX platform, see new features in action, and chat with our team about tools that help make scientific research more discoverable and accessible. Whether you're a longtime user or just learning about SciX, we'd love to meet you and hear about your research needs.

Summer AAS meetings are smaller, quieter, and in some ways make for better conversations than the larger winter meetings. If you will be in Pasadena June 14-18, look for Jennifer Lynn Bartlett, Project Scientist for Astrophysics. Although we will not have a booth, she will be presenting and conducting oral history interviews. She would be delighted to talk to you about the transition from ADS to SciX or anything else astronomical (or not, she can be rather chatty).

 AbSciCon 2026 Recap
AbSciCon 2026 RecapSciX was proud to exhibit at AbSciCon 2026, showcasing our platform to the vibrant astrobiology research community. If you missed us, you can find our iPoster “Science Explorer (SciX): Supporting Open and Interdisciplinary Science” or the other files on the Science Explorer Community on Zenodo.
The conference provided an excellent opportunity to connect with scientists, educators, students, and information professionals, many of whom visited our booth to explore SciX's tools and services. We enjoyed meaningful conversations, live platform demonstrations, and valuable feedback from attendees. The strong interest and engagement we received reinforced the importance of discoverability and access within interdisciplinary scientific research.
We look forward to building on the connections made at this year's meeting and supporting the interdisciplinary astrobiology community wherever you are. For more about the meeting and astrobiology content in SciX, read the full meeting summary.
Talks? Check. Posters? Check. Booth demos and conference swag? Also check. But our biggest takeaway from EGU 2026, held in Vienna, Austria in early May 2026, was the enthusiasm of the researchers who stopped by to explore SciX. Rather than writing a traditional conference recap, we're handing the microphone to scientists from across the globe who shared their thoughts on SciXplorer, research discovery, and the future of connected science. Read on to hear what they had to say.
Studying the aurora through citizen science means working across space physics, atmospheric science, public engagement, data validation, and more. In this month's guest blog, SciX Lead Ambassador Vincent Ledvina explains how SciX helps him make sense of this interdisciplinary landscape, revealing the connections between papers, authors, projects, and research communities that traditional literature searches can easily miss. It's a fascinating look at how modern research discovery works when science refuses to stay neatly within disciplinary boundaries. Read the blog post here!
Development and data holdings updates as of June 1st:
- Website and API Releases
- Updated the SciX Team photo
- Data holdings and pipelines
- 181k new records, and 5.7M new citations
Development details
- Bumblebee Releases
- v1.11.0 - [ops] Integrated FingerprintJS Pro visitor header for bot detection
- v1.10.16 - [improved] increased highlight analyzer limit to 1M
- v1.10.15 - [ops] dependency updates
- v1.10.14 - [improved] Update ORCID work types to match current doctypes
- Solr Releases
- v96.5.1 - [fixed] Removed invalid import
- Solr-Service Releases
- v1.1.6 - [fixed] Prevent duplicate windowed highlights
- [improved] Added performance instrumentation for dashboard comparison
May 2026
Announcements:
The SciX team is on the ground in Vienna this week for EGU26, and we’d love to connect! Stop by Booth X223 (downstairs) to meet the team, explore what we’ve been working on, and chat about how SciX supports your research.
We’re also excited to be part of the scientific program:
- Dr. Anna Kelbert, SciX Project Scientist for Earth Science, will present on Thursday at 5:10 PM during the ESSI3.2 session. Her talk will explore how SciX enables cross-disciplinary dialogue and improves credit attribution across research communities.
- Dr. Suze Kundu, our Research Community Engagement Coordinator, will be presenting a SciX poster on Friday from 4:15–6:00 PM in Hall X4 (X4.84) – stop by to say hello and learn more!
Whether you're curious about SciX or already using it, we’d love to see you there.

Next up, the SciX team is heading to Madison for AbSciCon 2026, taking place May 17-22! As one of the leading conferences in Astrobiology, AbSciCon brings together researchers from across disciplines – and we’re excited to be part of the conversation.
Ahead of the meeting, we’re also highlighting our work with the astrobiology community in a new blog post: “From Collaboration to Curation: Building NASA Astrobiology’s Living Bibliography in SciX”. It’s a behind-the-scenes look at how SciX supports cross-disciplinary research and helps make complex, distributed scholarship more discoverable.
Jennifer Lynn Bartlett, project scientist for astrophysics, will present “Science Explorer (SciX): Supporting Open and Interdisciplinary Science,” a poster in Session 227: Best Practices for Implementing Open Science on Tuesday, May 19 from 3:45 PM–5:15 PM CDT. The poster hall is on level 1 of the Monona Terrace.
If you’ll be attending AbSciCon, join us in the exhibit hall for a quick demo that can accelerate your science and show us what connections you are making across disciplines. We’d love to connect!
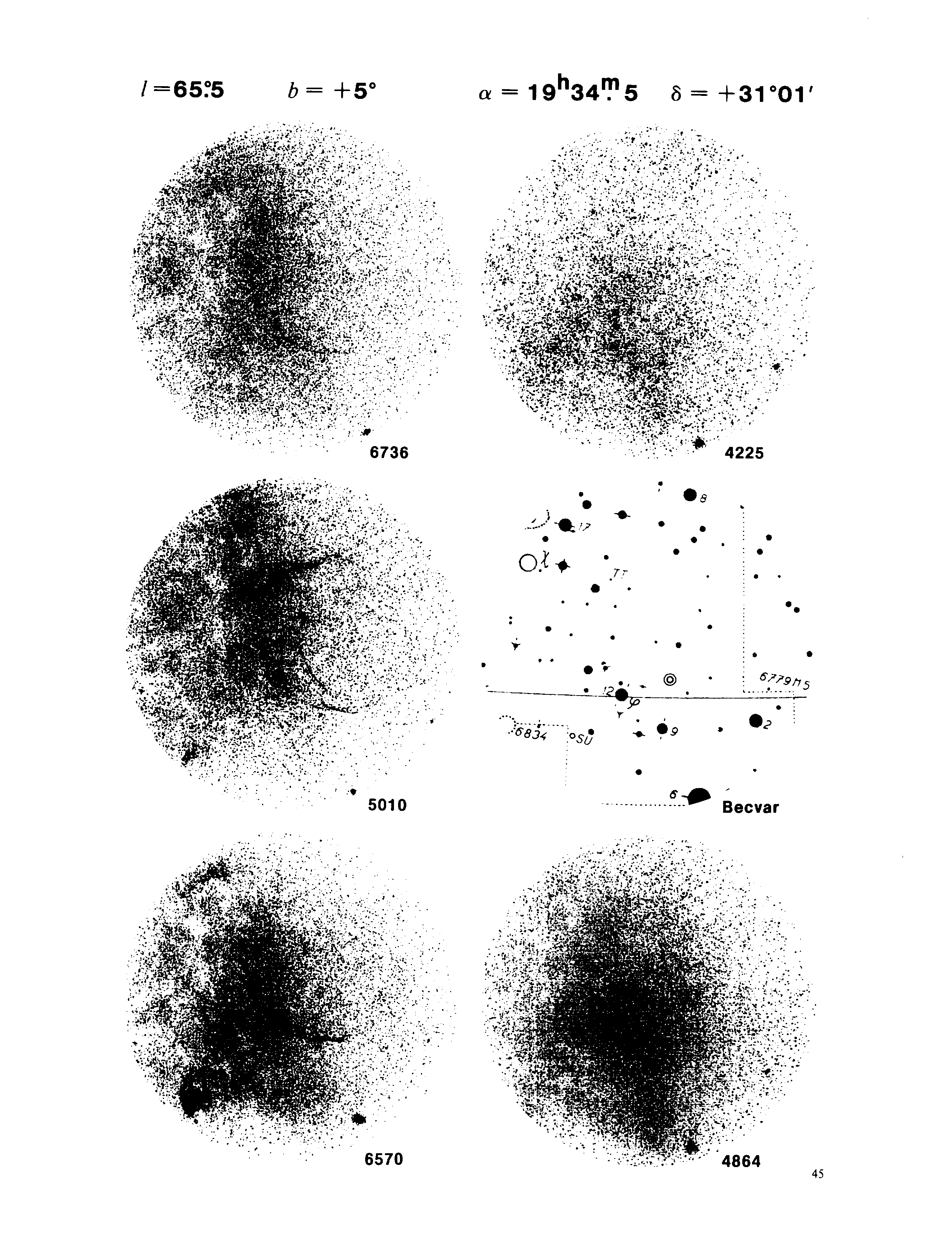

As shown in these scanned pages from the 1979 NASA publication “An emission-line survey of the Milky Way“, not every scan captures all the information present in the originals. At best, these views of our Milky Way are an observation of an observation of an observation. Therefore, when digitizing, retaining the original material if possible is desirable. Here, Ted Gull, one of the original authors, entrusted Jennifer Lynn Bartlett, project scientist for astrophysics, with the original photographic plate negatives. She plans to work with the Harvard Plate Stacks to scan these and make them available in SciX for everyone, However, given their current state and the need to raise funds to support scanning additional historical literature, this project is likely to take several years.

Andrew Harris, chair of the University of Maryland Department of Astronomy, hosted Jennifer Lynn Bartlett, project scientist for astrophysics, last month for a talk about how SciX benefits astronomers and how to adapt the new system to existing workflows. Folks were delighted with the advanced features, such as visualizations, and relieved that they would not have to give up old friends, like the “Classic” form. Jennifer was grateful for their hospitality and appreciated the opportunity to meet with colleagues in person while she was in Maryland.
If your department or project would like a presentation about SciX, please contact jennifer.bartlett@cfa.harvard.edu or adshelp@cfa.harvard.edu.
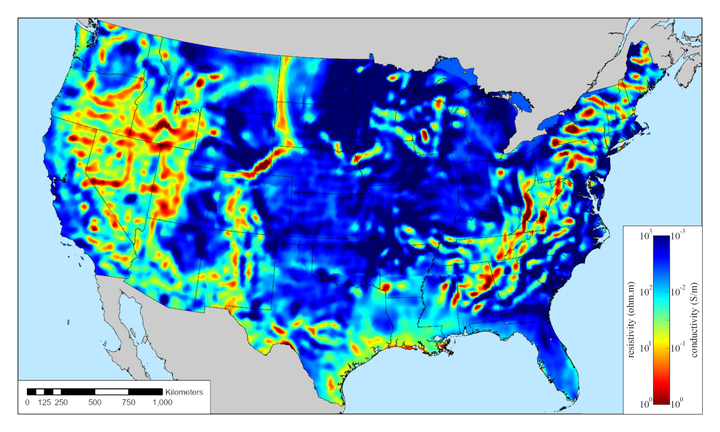
Our own Project Scientist for Earth Science, Dr. Anna Kelbert, is the lead author of a paper that has been making waves this week! The work was recently featured in press releases from the Harvard-Smithsonian Center for Astrophysics, Science, and USGS.
By mapping electrical conductivity of the Earth’s crust and upper mantle across the continental United States, the team discovered that the Appalachian Mountains and the mid-continent sit on ancient continental fragments left over from long-vanished tectonic collisions. This research supports important Earth science applications, including the United States’ capability to mitigate natural geomagnetic hazards that can disrupt the power grids we rely on. The paper reminds us that the ground beneath our feet is anything but simple. What looks like stable, familiar geology is actually a result of complicated dynamics, a stitched-together patchwork of Earth’s deep-time history with direct relevance to our technological present and future. Read the open access paper to learn more!
Development and data holdings updates as of May 1st:
- Website and API Releases
- Added USNO to bibgroups page
- New blog post about our NASA Astrobiology Collaboration
- Updated the Lead Ambassadors about pages
- Data holdings and pipelines
- 198k new records, and 10.12M new citations
Development details
April 2026
Announcements:
-
Recent Workshop Highlight: Language AI in the Space Sciences
Several ADS and SciX team members participated in the Language AI in Space Sciences Workshop, which was held on March 9-12 in Baltimore, MD. Organized by the Space Telescope Science Institute (STScI), the European Space Agency (ESA), and the Astrophysics Data System (ADS), this unique, interdisciplinary gathering brought together astronomy researchers, AI and natural language processing (NLP) specialists, software engineers, and domain experts. Unlike traditional scientific conferences, the event was heavily focused on hands-on exploration, open discussions, and collaborative projects, allowing participants substantial unstructured time to experiment with emerging tools and methods. The workshop offered a highly interactive environment that fostered creativity and innovation, including tutorials, discussions, and hackathons. Contributions by the ADS team included a discussion on licensing and property rights by Alberto Accomazzi, a tutorial on Retrieval-Augmented Generation by Atilla Alkan, and a presentation on Multilabel Text Classification for Concept Assignment in Astrophysics Literature also by Atilla Alkan. Recordings of the workshop’s presentations are available at on Youtube.

-
Sharing the Science Explorer at APS Global Physics Summit 2026 Recap
 Project Scientist for Astrophysics Jennifer Lynn Bartlett was thrilled to spend a week in the mile-high city talking to physicists with a broad range of interests about how they can find what they are looking for in the SciX. As Glen Bennett, Swastika Acharjee, Naaz Shafeer Vemmerath Kulangara, and Liz Kruesi discovered, the SciX physics collection is extensive, easy to navigate, and free; we welcome new researchers and independent scholars. Read more about it in our blog post and please reach out if you have questions about the ADS to SciX transition or about accessing physics content effectively. Many thanks to the NASA Physics of the Cosmos team, especially Chief Scientist Brian Humensky and public outreach specialist Stephanie Clark, for sharing our Hyatt space with us and to Dan Cooke and all the American Physical Society staff who make sharing our science through the Global Physics Summits possible.
Project Scientist for Astrophysics Jennifer Lynn Bartlett was thrilled to spend a week in the mile-high city talking to physicists with a broad range of interests about how they can find what they are looking for in the SciX. As Glen Bennett, Swastika Acharjee, Naaz Shafeer Vemmerath Kulangara, and Liz Kruesi discovered, the SciX physics collection is extensive, easy to navigate, and free; we welcome new researchers and independent scholars. Read more about it in our blog post and please reach out if you have questions about the ADS to SciX transition or about accessing physics content effectively. Many thanks to the NASA Physics of the Cosmos team, especially Chief Scientist Brian Humensky and public outreach specialist Stephanie Clark, for sharing our Hyatt space with us and to Dan Cooke and all the American Physical Society staff who make sharing our science through the Global Physics Summits possible. -
Retirement of ADS and SciX’s Lead Project Scientist, Dr. Michael J. Kurtz
After decades of visionary leadership and unwavering dedication, the Astrophysics Data System (ADS) announces the retirement of our Project Scientist, Dr. Michael J. Kurtz. Michael joined the CfA in 1982 as a research astronomer in the OIR division, participating in both the CfA Redshift Survey and the Century Survey. Michael has been a cornerstone of the ADS since its inception in the early 1990s, helping transform the way researchers access scientific literature. Under his guidance, ADS was conceived and developed into the sophisticated, multi-faceted discovery engine that powers modern astronomical research today.
Beyond his visionary contributions to ADS, Michael is widely respected for his deep understanding of the intersection between information science and astrophysics. His research in bibliometrics and informatics have been widely recognized: in 2000 he received the ISI/ASIST Citation Award for innovation in bibliographic research; in 2001 the AAS awarded him the George Van Biesbroeck Prize for “for the visionary design of the Astrophysics Data System;” in 2018 he was given the best paper award by the Journal of the Association for Information Science and Technology. He is a fellow of the AAS, APS, and AAAS. While we will miss his insight and historical perspective in our daily operations, his legacy is firmly embedded in ADS and its successor, SciX. We invite you to join us in thanking Michael for his extraordinary service and wishing him a rewarding and peaceful retirement.
-
Do You Use the ADS Historical Observatory Publications?
 If you access the historical observatory publications through the “Historical scans currently in the ADS” page or the “Observatory/Society Publications Query Page for the Astronomy database” rather than through the primary ADS or SciX search pages, please contact Project Scientist for Astrophysics and occasional historian of astronomy Jennifer Lynn Bartlett (help@scixplorer.org). We would like your feedback on what these pages provide that our other interfaces do not. As we prepare to complete the transition from ADS to SciX, we plan to modernize these as well, as they have not been maintained for years.
If you access the historical observatory publications through the “Historical scans currently in the ADS” page or the “Observatory/Society Publications Query Page for the Astronomy database” rather than through the primary ADS or SciX search pages, please contact Project Scientist for Astrophysics and occasional historian of astronomy Jennifer Lynn Bartlett (help@scixplorer.org). We would like your feedback on what these pages provide that our other interfaces do not. As we prepare to complete the transition from ADS to SciX, we plan to modernize these as well, as they have not been maintained for years.
Development and data holdings updates as of April 1st:
- Website and API Releases
- Added Solar Dynamics Observatory to bibgroups page
- New blog post: APS 2026 Recap
- Data holdings and pipelines
- 594k new records, and 8.65M new citations
Development details
March 2026
Announcements:
Spring is in the air in the Northern hemisphere, while our friends in the Southern hemisphere enjoy the transition into cooler autumnal days. However the SciX team have been experiencing four seasons in a day - whether at SciX HQ in Cambridge MA, or on their conference travels in 50 shades of grey Glasgow! The team were out there representing SciX at the recent Ocean Sciences Meeting. Read on to find out what they got up to, and look out for us later this month in Denver CO for the APS Conference.
Wherever you are exploring science, stay safe, and we hope to see you soon!
-
Ocean Sciences Meeting 2026 Recap
 Jenny Koch and Suze Kundu from the SciX team spent last week in glorious Glasgow, UK where the annual Ocean Sciences Meeting took place. We spent four energising days meeting researchers working across land, sea, and sky. Read our blog post to discover what Claudette Proctor (Stanford) and Kayla Ellerbe (University of Miami) thought of the SciX platform, and find out how interdisciplinary ocean researchers like Bryan Wilson are using NASA’s ECOSTRESS data. While we did run out of our much-loved badges designed by SciX Lead Ambassador Yueyi Che, we made our own interdisciplinary connections with attendees. We even had brushes with royalty - in the form of a princess, and a boat. OSM 2026 was a joyful reminder that ocean science is global, collaborative, and brilliantly interconnected. Find out more in our OSM write-up!
Jenny Koch and Suze Kundu from the SciX team spent last week in glorious Glasgow, UK where the annual Ocean Sciences Meeting took place. We spent four energising days meeting researchers working across land, sea, and sky. Read our blog post to discover what Claudette Proctor (Stanford) and Kayla Ellerbe (University of Miami) thought of the SciX platform, and find out how interdisciplinary ocean researchers like Bryan Wilson are using NASA’s ECOSTRESS data. While we did run out of our much-loved badges designed by SciX Lead Ambassador Yueyi Che, we made our own interdisciplinary connections with attendees. We even had brushes with royalty - in the form of a princess, and a boat. OSM 2026 was a joyful reminder that ocean science is global, collaborative, and brilliantly interconnected. Find out more in our OSM write-up! -
See You At APS! The SciX team is heading to the 2026 meeting of the American Physical Society (APS) Global Physics Summit, March 15-20 in Denver, Colorado! We’re excited to connect with researchers, learn about the latest discoveries, and share how SciX supports the physics community. If you’ll be attending, be sure to say hello to us at the Hyatt Regency Denver alongside our NASA colleagues.
Development and data holdings updates as of March 1st:
- Website and API Releases
- Added new tutorial videos from Youtube
- Posted the ADSUG 2025 Report
- Data holdings and pipelines
- 4.42M new records, and 6.25M new citations
- Over 25k publications from the NASA Space Life Sciences Library newly indexed and a bibgroup!
Development details
- Export Service Releases
- v3.1.17 - [fixed] Fixes for AGU, AMS styles
- Journals Database Releases
- v1.3.5 - [improved] Added ‘year’ to completeness schema
- v1.3.4 - [ops] Export (bibcode, canonical abbreviation) to backoffice file
- Nectar Releases
- v0.45.0 - [improved] Show "Record Not Found" in abstract subpages if invalid abstract ID
- v0.42.3 - [new] Add access-level badges (open access vs paid) to full text sources
- v0.41.0 - [improved] Update ORCID work types
- v0.39.0 - [improved] Extract collection and property into query filters
- Solr Service Releases
- v1.1.5 - [fixed] Anonymous BigQuery handler was pointed at solr select endpoint
- v1.1.4 - [improved] Add Non-authenticated user check for handler
- v1.1.3.1 - [fixed] Minor bug that caused highlight queries to fail
- v1.1.3 - [new] Enable keyword & author highlights
- v1.1.2 - [ops] Set UID using new header name
- [fixed] In AASTeX-PSF moved title before journal name
- [improved] Modified sort order based on refereed status
- [improved] Minor change to pipeline command line options: converts input table names to lower case
- [improved] Set password minimum length to 8
- [improved] Improve add to library dialog
- [improved] Render feedback menu items as links for new-tab support
- [improved] Update access labels (open access vs paid)
- [fixed] Prevent facet requests from firing with empty query
- [fixed] Fetching results list bug
- [improved] Filter collections facet to exclude astrophysics, planetary, and heliophysics
- [improved] Redirect correction feedback form
- [improved] Add reset to defaults button on settings pages
- [improved] Make search results items more compact
- [fixed] Search results loading layout bug
- [fixed] Filter empty string orcid values
- [fixed] Prevent truncation of math-heavy abstracts
- [fixed] Typo in visualizations error message
- [improved] Add discipline routes, fix legacy referrer, rename General Science in discipline drop-down menu to “no preferred discipline”
- [improved] Expand authors-per-result preference to 1-50
- [new] Windowed Highlights
- [improved] Remove empty highlights
February 2026
Announcements:
What a start to the year it has been! With the transition from ADS to SciX in full swing, the SciX team has been meeting with members of the SciX Community at meetings and conferences all over. Our goal is for the astronomy community to experience SciX as early as possible and step up to the next generation of literature search and more by the end of 2026. Read on to find out more about where we have been, where you’ll find us next, and some of the most recent developments for Science Explorer, your one-stop shop for research discovery, innovation, and impact, helping you “keep it 100 on the land, the sea, the sky”.
-
Transition to SciX
Alberto Accomazzi, Principal Investigator, gave a talk at AAS247 about the benefits of moving to SciX now at the NASA hyperwall. If you weren’t there or you missed our resource links last month, check out our ADS to SciX page and dive in to our Quick Start guide!Our current SciX transition outreach efforts are focused on showcasing the platform’s power to support astronomical research. Our expanded collections provide access to greater interdisciplinary papers and resources from other disciplines that can make our work easier, in addition to the increasing number of references and citations connected with our system. Astro researchers who tried SciX during recent conferences were pleased by how similar the interface is to ADS, as well as its new features like smooth resizing for a mobile-friendly experience and one-click “copy and paste” citations.

-
Get Involved! Create a Multi-Label Text Classification Dataset with ADS
Please help us build an open annotated dataset for multi-label text classification in astrophysics that will further strengthen the discoverability of astronomy research in SciX!. Together, we will create a high-quality training resource to support the development of language models capable of automatically assigning scientific concepts (keywords) to research papers. Such models will enable future information-retrieval tools for astrophysics.Motivation: Developing robust models for automatic keyword assignment requires carefully annotated training data. Therefore, we will target a representative set of astrophysics research papers and annotate each with the relevant Unified Astronomy Thesaurus (UAT) concepts. Once completed, the dataset will be openly released and will support downstream applications, including automated indexing, topic discovery, and improved literature search capabilities within ADS/SciX.
What Participation Involves: You should be willing to read 5–10 full papers and assign the UAT concepts that best describe their scientific content, following our annotation guidelines. In addition, you will highlight the text fragments that justify each selected keyword. The selections will help with explainability and model interpretability. Finally, you may be asked to participate in a virtual discussion to finalize keyword selection when annotators disagree on their selections.
How to Participate: Please indicate your interest using this short form. We will follow up to provide the annotation guidelines, example annotations, and access to the annotation interface. Please contact Atilla Alkan with any questions. We hope you will collaborate with us to build a shared, reusable dataset to benefit the entire astrophysics community.

-
AAS247 Round-Up
SciX team members, Alberto Accomazzi, Atilla Alkan, Carolyn Grant, Edwin Henneken, Jennifer Lynn Bartlett, and Mugdha Polimera, enjoyed meeting so many new users and old friends at the 247th meeting of the American Astronomical Society held in Phoenix, AZ during the first full week of January.Olivia “Harper” Wilkins, Dickinson College chemistry professor and SciX Lead Ambassador, co-led our workshops on Sunday afternoon. Everyone contributed to staffing the booth, which featured stickers with artwork of Yueyi Che, PhD student at UC Irvine and SciX Lead Ambassador.

Mugdha, back-end developer, presented “The Future of Scientific Discovery: Responsible AI/ML Enhancements in ADS and SciX” describing how we enrich our collections and enable you to search for papers, datasets, and software in more nuanced ways.
Atilla, AI/ML postdoctoral researcher, presented “Concept Classification Across Scientific Domains: Adapting to the Unified Astronomy Thesaurus’s Expansion into Heliophysics” describing our approach to automated classification of scientific records to accelerate discovery and improve search.
Jennifer, project scientist for astrophysics, presented “Science Explorer: Open Science Discovery Engine” describing a Library Carpentry course for new SciX users. She also presented “Science Explorer and StarGlass: the Future of the Historical Sky” demonstrating the linking of astronomical photographic plates (observations) to articles and logbooks. In addition, she organized splinter sessions for the Working Group on the Preservation of Astronomical Heritage and the Working Group on the Unified Astronomy Thesaurus (UAT). SciX continues the ADS tradition of making the historical literature of astronomy accessible to scientists, historians, and educators. The UAT is our preferred vocabulary for astronomy concepts and keywords; improving its content and its use will improve searches for astronomy topics and help make connections among similar ideas in other disciplines.
-
AMS 2026 Round-Up
Team members Kelly Lockhart, Daniel Chivvis, and Anna Kelbert joined thousands of others in braving the thing they love most - BIG WEATHER - to attend the American Meteorological Society conference in Houston, Texas, at the end of January. Anna, the Project Scientist for Earth Science at SciX, gave a talk titled “Discovering Space Weather Resources in Science Explorer using Keyword Enrichments” at a session focused on the current state and future of space weather research.We loved meeting you all and hearing about the unique challenges that you are helping overcome. The AMS meeting is a real opportunity to see how interdisciplinary research leads to impactful realities. From atmospheric aerosols to Zonda winds, SciX has your research A-Z covered.

-
AGU OSM - February 2026, Glasgow UK
If you missed us at AGU, AAS, AMS, or any other conference with a three-letter acronym, don’t fear because we’ll soon be at more conferences with three-letter acronyms! We just can’t get enough of interacting with our community. We’ll be attending the Ocean Sciences Meeting in Glasgow, UK at the end of February. The team will be on hand to answer any questions you might have about how you can use this free and open platform to explore the kind of interdisciplinary research that lurks in the depths of the sea. We’ll also be bringing some of our cute swag, and if you can successfully use the clues to Guess the Science Explorer, you’ll also be in with a chance of winning some very exclusive SciX merchandise! Swing by Booth Number 85. We look forward to seeing you there - as they say in Scottish Gaelic, tha mi air bhioran!

-
By Scientists, For Scientists
Mugdha Polimera, SciX back-end developer and astrophysicist, shone in her dual roles at AAS247 with her presentation on “From Dwarfs to Giants: A Complete Census of AGN Across the RESOLVE and ECO Surveys.” She and her co-authors show the demographics of active galactic nuclei (AGN), i.e., actively accreting supermassive black holes, and their hosts shift dramatically with galaxy mass.The results show that AGN are more common in dwarf galaxies than most previous surveys suggested, but also reveal a sharp increase in AGN frequency in transitional galaxies around the same mass as the Milky Way. They argue the transition reflects how the cold gas accretion in the host galaxies and the dark matter mass of the group haloes could regulate black hole growth and star formation.
Check out the January 8 press conference and press release featuring her work!

Development and data holdings updates as of February 1st:
- Data holdings and pipelines
- 128k new records, and 2.48M new citations
- Over 4300 NASA Earth Science proposals newly indexed
Development details
- Bumblebee Releases
- v1.10.13 - [new] Added setting to view ALL authors per search result
- v1.10.12 - [ops] Recaptcha authorization
- v1.10.11
- v1.10.10 - [ops] Recaptcha loading and error tracking
- v1.10.9 - [ops] Redirect url pattern
- v1.10.8 - [new] Menu and button for ADS to Scix transition
- Nectar Releases
- v0.37.7 - [new] Added the ability to adjust items per page on abstract subpages
- v0.34.14 - [new] Added tooltips in search results page
- Solr Releases
- [improved] Strip HTML tags from document title on abstract pages
- [improved] Added UAT to all search terms dropdown
- [new] Implement 'authors per result' user preference
- [improved] Updated quick citation format list to display most popular formats
- [improved] Adjusted font colors, font sizes, icons sizes to improve readability
- [improved] Redirect users to original page after login
- [improved] Made landing page form selection sticky
- [improved] Strip HTML tags from title in browser tab and meta tags
- [fixed] Use OR operator for multiple collections in classic form
- [fixed] Icon not shown on Safari
- [fixed] Show 'back to results' link when query is *:*
- [fixed] New line not shown in html citation
- [fixed] Show ORCiD session expired warning only once
- [ops] Error handling, performance, and robustness
- [ops] Dependency updates
- [ops] Sanitized middleware logging and added tracing headers
- [new] Added 'By ADS' to logos when in astrophysics, heliophysics, or planetary modes
- [improved] Add back buttons for tours
- [improved] Enhanced metadata tags for full ADS parity
- [improved] Improved the visibility of the Highlights button and now label each highlight with its source field for clearer context
- [fixed] Removed n param from url
- [fixed] Library copy citation bug
- [fixed] Prevent ADS mode reactivation on page load/navigation
- [ops] Dependency updates
- [ops] Improved middleware test coverage
January 2026
Announcements:
Happy New Year!
We are thrilled to bring you the first SciX Newsletter of the year. In last month’s newsletter, we reflected on a year of evolution. As we embark on a brand new year, and with our future secured thanks to some recent funding-related good news, our focus and commitment to ensuring a seamless transition from ADS to SciX and a smooth onboarding for new SciX users remain our main priorities.
With that in mind, as always, if you have any questions, please don’t hesitate to contact us by email at help@scixplorer.org, or by using this feedback form. Thanks for being a valuable and valued member of our community.
-
SciX at AGU25
We had a great time meeting SciX-curious attendees at #AGU25 last month! From existing ADS users that have already made the switch, to people brand new to our platform, we were excited by the research community’s excitement for the platform. We are always keen to showcase our user stories, so if you’ve been using SciX to help accelerate your research discovery, innovation and impact and want to tell your story via a short video or a post on our blog, get in touch.Whether you saw one of our or our Ambassador’s panel discussions, posters, NASA hyperwall talks, or whether you managed to grab one of our hundreds of SciX badges before they ran out on the last day, thanks for engaging with us. If you missed us, look out for us at #AAS247. We’ll also be attending AMS and OSM in the next couple of months. If you’d like to arrange a chat with one of our team to find out more about SciX, please let us know.

Development and data holdings updates as of January 1st:
- Website and API
- Data holdings and pipelines
- 168k new records, and 3.86M new citations
Development details
- API Gateway Releases
- v1.2.4 - [improved] Added nectar feedback form
- Nectar Releases
- v0.29.2 - [new] Added 'keyword' and 'author' fields to highlights
- Solr Service Releases
- v1.1.1 - [improved] Enabled boost type mapping
- [improved] Empty abstract graphics state
- [improved] Auto-set ASTROPHYSICS mode for legacy ADS users
- [fixed] Prevented undefined error in AbstractSideNav
- [fixed] Authors field edit bug
- [fixed] Restored notifications on login page and added ADS credentials message
- [fixed] Abstract page title to show paper title on direct navigation
- [ops] Enabled injecting query parameters
December 2025
Announcements:
We can’t believe it’s already December. As we look back on another year of supporting research, we want to take a moment to thank you, our loyal user community. ADS and SciX are made by scientists, for scientists, and we couldn’t do any of this without your feedback. With all that being said, this month’s newsletter contains some news about the future of our platforms. We want to assure all of our users that we are committed to working through these impending changes with you. As such, if you have any questions, please don’t hesitate to contact us by email at help@scixplorer.org, or by using this feedback form. Thanks for being a continued part of our community. Read on to find out more.
-
ADS is Evolving in 2026
2026 will be a transition year for ADS users, as the astronomy community moves to the astrophysics version of SciX. Our development team is working to ensure that astronomers have as smooth a transition as possible. In all of this, we remain committed to serving the astronomy community.- In the meantime, ADS users will be glad to know that:
- You can use your existing ADS account with SciX; sign in with the same credentials
- Your libraries, settings, and notifications will continue as is
- Your links will be automatically redirected; you will not need to change any of them
- You can still use the Classic interface in SciX
- Choosing the astrophysics discipline prioritizes astronomy results in your searches, or you can restrict your searches to our astronomy and physics collections for a more focused ADS-like experience.
- When you switch to SciX, you get the benefits of:
- Astrophysics-focused literature, data, and software searches within a larger multidisciplinary collection

- Improved speed and reliability, including a dashboard to check system status if you need it
- Better accessibility compliance so that all scientists can access our resources
- Mobile-friendly interface that adapts to smaller screens for working wherever you are
- Copy-and-paste citations
- NASA and NSF proposals, awards, and associated papers
- Links among papers, proposals, data, and software through less formal mentions and credits in addition to traditional citations
- Searchable filters for narrowing your search
- Type-ahead support to help you formulate queries
- Tags on abstract pages that identify refereed status, collection, document type, and bibliographic group
- [beta] concepts assigned from the Unified Astronomy Thesaurus (UAT) providing a consistent set of keywords across astronomy papers, datasets, and software
Keep an eye out for links to more information, including onboarding tutorials, and lived-experience testimonials from existing ADS users that have transitioned into regular SciX users. If there are any other resources that you feel would benefit the astro community in this transition, please share your thoughts with us, either by email at help@scixplorer.org, or via this feedback form.
This exciting step into a new era of ADS’s long established history will help you expand the reach of your research, and unlock a huge amount of previously untapped collaborative potential, making your research even more impactful than it has been before. We are looking forward to going on this journey with you, and we are so excited to see how the expanded SciX coverage supports your work. If you just can’t wait, head on over to our Quick Start Guide and start exploring for yourself!
- Astrophysics-focused literature, data, and software searches within a larger multidisciplinary collection
- In the meantime, ADS users will be glad to know that:
-
SciX Workshop at AAS 247
 Jump into SciX and accelerate your research with our “Exploring SciX: A Researcher’s Guide to the Science Explorer Platform” Workshop on Sunday, January 4 at the American Astronomical Society Meeting. Three complimentary (FREE!) 1-hour sessions will be offered at 1 PM, 2 PM, and 3 PM in Phoenix Convention Center, Room 126 A. Whether you are an old ADS hand who is ready to transition to a multidisciplinary environment or a new researcher who needs to navigate your first literature search effectively and efficiently, you will find the resources and support you need in one of these sessions.
Jump into SciX and accelerate your research with our “Exploring SciX: A Researcher’s Guide to the Science Explorer Platform” Workshop on Sunday, January 4 at the American Astronomical Society Meeting. Three complimentary (FREE!) 1-hour sessions will be offered at 1 PM, 2 PM, and 3 PM in Phoenix Convention Center, Room 126 A. Whether you are an old ADS hand who is ready to transition to a multidisciplinary environment or a new researcher who needs to navigate your first literature search effectively and efficiently, you will find the resources and support you need in one of these sessions.We have been working with AAS staff to reconfigure this workshop to make it available to as many people as possible. You should be able to register for the shorter, free sessions through the AAS registration site shortly. If you have already registered for the meeting, you can just add this event to your registration.
If you will be at AAS but you can’t make the workshop, please stop by our booth for a demonstration. You will like what you see.
-
2025 ADS Users Group Meeting
The ADS Users Group met on November 20 and 21 to review how well ADS and SciX are performing, to assess progress towards our vision of a single multidisciplinary digital library, and to prioritize goals for the coming year. With continuing budget uncertainty, we provided plans based on two scenarios: full funding for both ADS and SciX and funding for ADS only. While SciX met expectations and launched as a fully functional interface to our extensive collections in September, the 2025 ADS User Survey showed that the astronomical community remains uncertain about embracing a new access point, only six years after the last major revision. While we wait for the ADS Users Group report, you can see our presentations online.

-
See You At AGU25!
Some members of the SciX team will be at the AGU25 Conference in New Orleans later this month. Swing by booth #1532 to learn more about the platform and discover how it can catalyse your research, discovery and impact in the Earth, ocean and planetary sciences!We will also be giving talks, demos and presenting posters at the conference so we hope our paths cross with as many current and future users as possible!

Development and data holdings updates as of December 1st:
- Website and API
- [new] Updated ADSUG charter; added ADSUG 2025 meeting
- [improved] Updated links on help pages
- Data holdings and pipelines
- 582k new records, and 10.72M new citations
Development details
- Bumblebee Releases
- v1.10.7 - [fixed] Loading for empty affiliations being displayed
- Nectar Releases
- v0.26.0 - [new] Added journal autocomplete and enhanced UAT search
- v0.25.1 - [new] Added readable publication date formatting
- Resolver Gateway Releases
- v2.1.3 - [fixed] Remove forced redirect for links not in the valid referrers list
- v2.1.2 - [improved] Updated SciX logo url for landing page
- Resolver Service Releases
- v2.0.27 - [improved] Converted link subtype to be case insensitive
- Solr Releases
- v96.2.0 - [improved] Enabled other identifiers in bitset query parser
- [ops] Feedback integration update
- [improved] Updated help link to /scixhelp/
- [improved] Fetching of associated materials
- [improved] Display of abstract page metadata
- [fixed] Added validation of `pageSize` to fix pagination errors
- [ops] handle forbidden user settings fetch gracefully
- [ops] Updated SciX ID prefix to special case queries
November 2025
- Announcements:
-
SciX visits San Antonio for GSA Connects 2025
San Antonio served up sunshine, science, and a whole lot of curiosity at this year’s GSA Connects 2025, held at the Henry B. González Convention Center. Against the backdrop of the city’s iconic River Walk and limestone heritage, the SciX team joined thousands of geoscientists, data specialists, and Earth explorers for a week of discovery and dialogue.
Our mission? To show how open and FAIR research platforms can help bridge disciplines and catalyse collaboration - because the biggest challenges on (and beyond) our planet can’t be solved with research that lives in a single science silo.
Through our booth and Dr Anna Kelbert’s demo-talk on the Innovation Stage, we had the pleasure of meeting SciX users old and new - and we’d love to see more of you at the AGU conference in New Orleans next month!

-
ADS Survey
 If you have not already let us know what you think about how ADS is performing, please complete our survey soon. We value your feedback. However, we are currently making upgrades only to the SciX interface because we will eventually have to consolidate all our users on a single platform. Therefore, we are especially interested in knowing whether you have tried SciX.
If you have not already let us know what you think about how ADS is performing, please complete our survey soon. We value your feedback. However, we are currently making upgrades only to the SciX interface because we will eventually have to consolidate all our users on a single platform. Therefore, we are especially interested in knowing whether you have tried SciX. -
ADS Users Group Meeting: Nov. 20-21
The ADS Users Group will meet virtually on November 20 and 21 to review the state of ADS and operational plans for next year. Community guidance is especially important as we strive to support researchers in this challenging and uncertain environment. Please let either the chair or the PI know of any issues they should consider or contact the PI for an invitation to the public sessions. We will be updating the ADS Users Group webpage as the meeting approaches with the newest members and planned presentations. -
LISA 10
 Edwin Henneken, Content, Curation & Collaborations Lead, and Jennifer Lynn Bartlett, Project Scientist for Astrophysics, presented virtually at the Library and Information Services in Astronomy meeting at the beginning of this month. Edwin presented on how the ADS/SciX links to and indexes data products. Jennifer discussed recent work to apply keywords from the Unified Astronomy Thesaurus (UAT) automatically to astronomy papers, datasets, and software to make them more easily findable. SciX Ambassador Manuel Pichardo Marcano translated the presentation into Spanish.
Edwin Henneken, Content, Curation & Collaborations Lead, and Jennifer Lynn Bartlett, Project Scientist for Astrophysics, presented virtually at the Library and Information Services in Astronomy meeting at the beginning of this month. Edwin presented on how the ADS/SciX links to and indexes data products. Jennifer discussed recent work to apply keywords from the Unified Astronomy Thesaurus (UAT) automatically to astronomy papers, datasets, and software to make them more easily findable. SciX Ambassador Manuel Pichardo Marcano translated the presentation into Spanish.
-
- Development and data holdings updates as of November 1st:
- Website and API
- [improved] Updated Bibcodes help page
- [improved] Updated Data FAQ page
- [improved] Updated positional field search information for last author searches
- [improved] Speed improvements
- Data holdings and pipelines
- 561K new records, and 5.72M new citations
- Website and API
Development details
- Bumblebee Releases
- v1.10.6 - [fixed] DOI disappearing during after loading an abstract
- v1.10.5 - [fixed] Author load issue on abstract pages
- v1.10.4 - [fixed] Year/citation graph loading issues
- v1.10.3
- v1.10.2 - [improved] Added banner for partial results
- Nectar Releases
- v0.22.42 - [improved] Facet updates and fixes
- v0.22.35 - [new] Added last author search to All Search Terms menu
- v0.22.29 - [improved] Smartened the paper form bibcode query
- Resolver Gateway Releases
- v2.1.1 - [fixed] Error when no link type is specified
- v2.1.0 - [improved] Updated redirecting of links from classic articles service to scan-explorer
- Solr Releases
- v96.1.6 - [improved] Added fields to the data schema to be used with boost functions, supporting discipline specific rankings
- [improved] Use default query for empty classic form
- [improved] Optimized fetching of the search results to reduce payload size
- [ops] Added tags to search page queries for analytics
- [ops] Added null check when deleting all records from a library
- [improved] Show total credit count in search results when sorted by search count
- [fixed] Guard conditions for handling citation helper suggestions
- [fixed] Removed “-00” from pubdates without days
- [ops] Added ADS login note
- [improved] Updated “pub” search in quickfield dropdown and examples
- [fixed] Carousel bug
- [ops] Added JSON-LD metadata generator for abstract pages
- [ops] Properly reset the user state after login
- [ops] Added UI variant for ADS or SciX
October 2025
- Announcements:
-
SciX Has Officially Launched!
We are delighted to share that the non-beta version of SciX officially launched on September 29th! This milestone represents the culmination of our community’s collective effort to build a platform that expands on ADS and provides integrated access to research across Earth, environmental and space sciences, including planetary science, heliophysics, geology, geophysics, atmospheric sciences and oceanography. Check out our new video here!You can access the platform at scixplorer.org.
You can also read our launch blog post, read the NASA Science Data Portal’s news item, and read the Center for Astrophysics Harvard & Smithsonian’s press release too!
As part of the launch, we’ll be sharing updates and news across social media, and it would be wonderful if you could support us in three simple ways:
1. Keep an eye out for SciX launch posts on our social media channels and amplify them through your own networks - we are @SciXCommunity everywhere! LinkedIn 🔎 X 🔎 Bluesky 🔎 Facebook 🔎 Instagram 🔎 Mastodon
2. Provide us with a short testimonial about SciX - why it matters to you, to your field, or to the broader research ecosystem
3. Invite at least two colleagues (ideally from diverse areas of research) to also share a testimonial. Personal recommendations go a long way in highlighting the value and impact of SciX - please let us know if we can help with this.
Thanks for embarking on this journey with us - we are so happy to have you on board!

-
Professional Development Training - Register Your Interest!
Are you a current ADS user curious to learn more about how you can further elevate your research with the extra functionality offered by Science Explorer (SciX), or are you a current SciX user that wants to learn more about how you can utilize all the fantastic features on this new platform to support your work? Then register your interest in our professional development training program using this form! Once we have an indication of the best formats for this training to take place, we will be in touch with more information. Engaging with our users helps us build a platform that best suits the needs of the research community, and every bit of feedback helps us as well as the broader research landscape, so please share the link with your colleagues and collaborators.
-
- Development and data holdings updates as of October 1st:
- Website and API
- [new] SciX Homepage
- [new] New Quick Start help page
- [new] Blog post celebrating SciX Launch
- Bumblebee releases:
- [new] Added PubMed full source links
- [improved] Added link to system status page in footer
- [fixed] Updated submodule for feedback form bug
- Export Service releases:
- [improved] Added support for BibTeX
techreportdocument type - [fixed] ASCL BibTeX format
- [improved] Added support for BibTeX
- Nectar releases:
- [improved] Landing page updates
- [improved] Tooltips for abstract page
- [improved] Improve search error message
- [improved] Allow facet download at different levels
- [fixed] Author affiliation form load error with some queries
- [fixed] Notifications on protected pages
- [fixed] Facets are now correctly applied in 2nd order operations
- [ops] Updated SciX email contact for Feedback and Help pages
- Data holdings and pipelines
- 510K new records, and 8.44M new citations
- This month we have added several noteworthy data holdings, included but not limited to:
- 1.25 million journal articles from IEEE
- 63K conference abstracts from the Goldschmidt conference series
- 33K technical reports from NASA’s NTRS
- 16K datasets from USGS
- 6K software records from USGS and DOE
- Website and API
Development details
September 2025
- Announcements:
-
SciX is Out of Beta and Ready for Take-Off!
Help us gear up for launch! Science Explorer’s Beta label has officially been removed, and momentum is building as we prepare for our full launch of the platform on 30th September. This is an exciting milestone for the community, and we’d love your help in spreading the word. Keep an eye out for SciX launch content across our social media channels, and please share it with your networks, colleagues, and collaborators. Together, we can make sure that more researchers discover the power of SciX.If you’re already a SciX user and would like to be part of our launch, we are collecting stories from our users about how the tool has revolutionized their research. If you would like to share your own story, either by text or in a short video, follow this link to complete the form.

-
Professional Development Training - Register Your Interest!
Are you a current ADS user curious to learn more about how you can further elevate your research with the extra functionality offered by Science Explorer (SciX), or are you a current SciX user that wants to learn more about how you can utilize all the fantastic features on this new platform to support your work? Then register your interest in our professional development training program using this form! Once we have an indication of the best formats for this training to take place, we will be in touch with more information. Engaging with our users helps us build a platform that best suits the needs of the research community, and every bit of feedback helps us as well as the broader research landscape, so please share the link with your colleagues and collaborators. -
“SciX Data Collections” Blog Post
We have published a new blog post about data collections in ADS/SciX! Tracking the use of research data and software in the scientific literature is one of the primary goals of SciX, and maintaining data collections is the primary way for users to discover them. This blog post describes how SciX curators generate and maintain these resources and how users benefit from having them integrated into the system. Please see the blog post for more details. -
SciX at the NASA Open Source Science Data Repositories Workshop
The Science Explorer was featured at the NASA Open Source Science Data Repositories Workshop, which was held in Huntsville, AL, August 25-27. The workshop brings together NASA data officers, repository data stewards, NASA-funded data producers, and NASA Office of the Chief Science Data Officer (OCSDO) leadership to discuss current issues collaboratively and identify potential scientific data and information solutions that can be developed and implemented across NASA Science Mission Directorate (SMD) repositories. Alberto Accomazzi, the SciX PI, gave two presentations: “What’s new with SciX” and “Metrics that Count with SciX,” in addition to a demo of the system. -
NASA Awards Indexed
We have added records for NASA Awards in astrophysics and heliophysics projects in an ongoing effort to index NASA science proposals and awards. In addition, we are enriching the records with respective award information from USASpending.gov, which supports searching by grant numbers. -
SciX at Sea
In July, Jennifer Lynn Bartlett, project scientist for astrophysics, sailed from Victoria, British Columbia, to San Francisco, California, on the Coast Guard Academy training ship, a three-masted barque, to assist with celestial navigation instruction. Despite global GPS coverage, sailors still need to know how to operate without it. With the cadets, she enjoyed drawing the connections that join sky and ocean. If you are more a sea enthusiast, then you should also appreciate SciX’s coverage of oceanography, including more than 15,000 open-access, refereed articles. For more than 500 oceanographic publications, we have linked them directly to their associated datasets. From Polaris to the Pacific, SciX is your guide to the scientific literature. -
Welcome to Our New Team Members
We are pleased to welcome new members to our team! Dr. Atilla Kaan Alkan joins us as a postdoctoral research fellow specializing in NLP for astrophysics. Dr. Suze Kundu joins us as Research Community Engagement Consultant in support of SciX initiatives. Learn more about them on our Team page!
-
- Development and data holdings updates as of September 1st:
- Website and API
- [new] SciX Data Collections blog post
- [new] Team page: Added Dr. Atilla Kaan Alkan and Dr. Suze Kundu
- Export Service releases:
- [improved] Added support of new doctypes (
instrumentandservice) - [improved] Edited manifest endpoint to update file extensions
- [improved] Added handling for MathML markup
- [improved] Added support of new doctypes (
- Nectar releases:
- [new] Added “Credits” and “Mentions” to left menu bar on abstracts’ pages, which display the software and datasets mentioned by a given paper or any papers that credit a given software package or dataset
- [improved] Added
boostTypeparameter to search based on the App Mode - [improved] Added warning message on potentially incomplete search results
- [fixed] Fixed issue with email input
- [fixed] Fixed an autocomplete menu behavior ensuring the menu closes when the first suggested item matches exactly the search input
- [fixed] Text overlap issue
- [fixed] Issue with alpha sorting in facets modal
- [fixed] Library pagination bug
- [ops] Updated logo
- Solr releases:
- [new] Added software mentions schema fields:
mention,mention_count,credit,credit_count - [improved] Updated the schema to include
reference_count
- [new] Added software mentions schema fields:
- Vault releases:
- [new] Added logic to convert myADS emails to SciX email notifications if notifications are created or edited in SciX
- [improved] Allow auto-updating of user library link servers
- [ops] Allow users to remove arxiv papers coming from
get other papersfor email notification - [ops] Allow for separate banners on ADS and SciX
- Data holdings and pipelines
- 289K new records, and 2.99M new citations
- Website and API
Development details
August 2025
- Announcements:
-
Professional Development Training - Register Your Interest!
Are you a current ADS user curious to learn more about how you can further elevate your research with the extra functionality offered by Science Explorer (SciX), or are you a current SciX user that wants to learn more about how you can utilize all the fantastic features on this new platform to support your work? Then register your interest in our professional development training program using this form! Once we have an indication of the best formats for this training to take place, we will be in touch with more information. Engaging with our users helps us build a platform that best suits the needs of the research community, and every bit of feedback helps us as well as the broader research landscape, so please share the link with your colleagues and collaborators. - Getting Resources Ready for a New Year
SciX has over 175,000 physics and astronomy education research articles; most are available in the PhysEd bibgroup. By submitting feedback, you can help us link the written descriptions to the associated supplementary materials that make these resources most useful:- Go to the “Feedback” dropdown menu at the upper right of the SciX web interface, and select the “Associated Articles” option.
- On the “Submit Associated Articles for the SciX Abstract Service” form, choose “Other” from the “Relation Type” dropdown menu.
- Describe the resource relationship briefly in the “Custom Relation Type” text box.
- Then, input the bibcode of the article and a link to the resource.
If we are missing something you use, let us know by selecting the “Missing/Incorrect Record” option on the “Feedback” dropdown. Sharing supplemental materials through SciX ensures these resources remain findable and accessible and continue to be reused.
- Astrometry: the “Old Astronomy”
In the late 19th century, a debate raged over whether astronomy was properly the study of the positions and motions of celestial bodies (astrometry) or could include techniques from the physics and chemistry laboratories (astrophysics). Project Scientist for Astrophysics Jennifer Lynn Bartlett is an astrometrist by training. She is going way back to basics and teaching naked-eye astronomy and constellation identification for the first half of this month. Lucky for us, she plans to rejoin the 21st century for the fall.
-
- Development and data holdings updates as of August 1st:
- Website and API
- Nectar releases:
- [new] Support of PubMed Central links in Full Text Sources
- [improved] Show download button to all facet modals
- [improved] Added system status page link in footer
- [improved] Added banner for system wide message
- [fixed] Improved search input, fixed bug that caused input to clear unexpectedly
- [fixed] Deduplicate incoming esource URLs
- [ops] Added key alias entry in search filter tuple (quadruple)
- Journals Database releases:
- [improved] Added
journals.master.deprecatedcolumn to squash unused bibstems - [improved] Updated pubtype sort in journal searches
- [improved] Updated summary display to convert
completeness_detailsfrom text to JSON
- [improved] Added
- Nectar releases:
- Data holdings and pipelines
- 1M new records, and 7.86M new citations
- Website and API
July 2025
- Announcements:
-
Reflecting on the first in-person meeting of the SciX Advisory Board
In June, members of the SciX Advisory Board and the SciX Team met in person for the first time. Following two successful remote meetings, those that were able to travel convened at the Center for Astrophysics | Harvard & Smithsonian with other participants joining online for two days of discussion and workshopping on the capabilities, coverage and community engagement aspects of the SciX platform, ahead of the full launch later this year. It wasn’t all work though - the team were also treated to a tour of the Great Refractor, once the most powerful telescope in the United States, right here in the department. This historic in-house telescope is a reminder of the deep roots the department has in space-related research, and while the team discussed the future of the field and how SciX can best support it, the highlight for many was getting to sit in the astronomer’s seat of the telescope! You can find out more about the Advisory Board’s members here. -
“The Power of Visualizations”, New Blog Post by SciX Ambassador, Sarah Lamm
In this blog post, SciX Ambassador Sarah Lamm explores the powerful visualization features that SciX offers. Lamm highlights the varied options and how this expands their interdisciplinary research capabilities. Read along to learn more about how Lamm utilises the powerful SciX visualizations like the author network, concept cloud, and metrics to enhance and focus their queries. - Enriching Navigation Conference Information
Did you, or someone you know present, at:- High Precision Navigation, 1989 International Workshop;
- Nav ‘89 Satellite Navigation, Royal Institute of Navigation;
- Viking Navigation, 1979, NASA, or;
- International Conference on Maritime and Aeronautical Satellite Communication and Navigation, 1978?
If so, we would like to include their paper in SciX. Anyone can submit a missing abstract, conference proceeding, or article using the “Feedback” dropdown menu at the upper left of the SciX website. Select “Missing/Incorrect Record” and provide us with as much detail as you can. Every addition makes the system better for everyone.
-
Share Your iPoster
Did you present an iPoster at the June meeting of the American Astronomical Society? Your abstract is already available in SciX. However, you can add a link to your iPoster for those who were unable to attend your session. From the “Feedback” dropdown menu at the upper left of the SciX website, select “Associated Articles..” After providing your contact information in case we have any questions, select “Other” from the “Relation Type” dropdown menu. For the free form “Custom Relation Type” field, type “iPoster link” or something similar. Then, provide the bibcode from your iPoster abstract listing; use the copy button when you look it up. Finally, provide the link to your iPoster. - Has Sextant. Is Traveling.
Even in our modern era of satellite navigation, celestial navigation remains a critical back-up system. During July, Jennifer Lynn Bartlett, project scientist for astrophysics, will be on the Pacific ocean assisting with the training of Coast Guard cadets using traditional instruments and visual observations.
-
- Development and data holdings updates as of July 1st:
- Website and API
- [new] Blog post: “The Power of Visualizations” by Sarah Lamm
- [new] Blog post: “Introducing the SciX Advisory Board” by Anna Kelbert
- [new] Export Service: Added AASTeX (PSJ), and added new table of contents endpoint to list all export endpoints and their types
- [improved] Help pages: Added Pubspace and USGS bibgroup descriptions
- [improved] Nectar:
- Support for Unified Astronomy Thesaurus (UAT): Added keyword auto-complete for terms, enhanced dropdown with related UAT keywords including parents and children, and improved accessibility and responsiveness of the UAT keyword dropdown
- Improved support for quoted and partial keyword searches
- Fixed issue with trending queries showing incorrect results
- Added internal API support to improve keyword search reliability
- Updated default sort order for more consistent results
- Adjusted link behavior for better compatibility
- Updated README with a new project banner
- [improved] Solr:
- Bumped the max clause count to re-enable first author searches
- Added a 10 second timeout to queries to improve service reliability
- Enforced highlight length caps set by publishers
- [fixed] API Gateway:
- Fixed Feedback Email Subject Format
- Fixed bug caused by behavior change in
urljointhat broke https link resolution - Added more descriptive error message when users query the API with
Bearer:$TOKENinstead ofBearer $TOKEN
- [fixed] Bumblebee: fixed signup form error messages
- Data holdings and pipelines
- 287k new records, and 9.24M new citations
- Website and API
Development details
June 2025
-
Announcements:
NSF Awards Indexed
We have added records for 466,730 awards awarded by the National Science Foundation across all directorates and divisions. Most of these records contain the project title, PI name and affiliation, award number, project start date, proposal abstract, and project outcomes report. These records are searchable by using doctype:proposal pub:”NSF Award”.In addition, we are currently working on linking existing publications to these award records. It is common practice to acknowledge when the research that produced a publication was supported by a funder, and to provide the award number. Taking this into account, we have identified over 98k publications that were supported by one or more NSF awards.
NASA DAACs Datasets Indexed
We now have about 10k datasets from the NASA Distributed Active Archive Centers (DAACs) indexed, with about 5k citations. Discover more by searching doctype:dataset pub:”Distributed Active Archive Center”.Meet us at AAS 246!
Will you be at the American Astronomical Society meeting this month? Stop by iPoster #104.02 (terminal 7) on Monday, June 9 from 9 AM to 10 AM AKDT and talk to Jennifer Lynn Bartlett, SciX project scientist for astrophysics. She is presenting “A Plate in Her Hand”, which begins to connect the female computers working in Harvard’s “great library of glass” by the astronomical photographic plates they used. Such plates were the only mechanical detector available to astronomers before the 1970s. As these archives are digitized, SciX would like to connect these valuable datasets to the corresponding literature.Got Images? Graphs? Video?
The Sixteenth Biennial History of Astronomy Workshop will explore visual practices in the production and transmission of astronomical knowledge this month. In SciX, we see the evolution of visualizations in the scholarly literature. For instance, E.E. Barnard (1894) provided a sketch of stars in “Great Photographic Nebula in Orion”. Today, Monthly Notices of the Royal Astronomical Society provides graphics files that can be previewed by clicking “Graphics” on the menu on the left side of the abstract view.In addition, you can add an author video to your paper or iPoster link to your conference abstract in SciX. Submit your link through the “Associated Articles” option on the “Feedback” dropdown menu and, then, choose “Other Relationship Type.”
At the Workshop, SciX project scientist for astrophysics Jennifer Lynn Bartlett will be presenting “Astronomical Photographic Plates: More than a Century of Service”, which describes the modern scientific, historical, and cultural roles of astronomical photographic plates.
-
Development and data holdings updates as of June 1st:
- Website and API
- [fixed] Export service journal format bug
- [fixed] Fixed URL for NASA SMD whitepaper blog post
- [fixed] Help pages: Fixed contact name to Alberto for permissions
- [improved] Help pages: Updated the Bibgroups page and added some new descriptions
- Data holdings and pipelines
- 524k new records, and 10.3M new citations
- Website and API
Development details
- Export Service Releases
May 2025
-
Announcements:
EGU 2025
Mike Kurtz, project scientist emeritus, and Jennifer Lynn Bartlett, project scientist for astrophysics, presented the advantages of searching the literature using SciX to over 500 earth scientists at the European Geosciences Union meeting in Vienna, Austria last month. Mike explained “Enhancing Geoscience Collaboration and Discovery: Leveraging the Science Explorer (SciX) for Efficient Literature Review and Interdisciplinary Research” and gave a live demonstration during an oral session on April 30. In addition, they gave multiple presentations of “Science Explorer: Accelerating the Discovery of NASA Science” on the NASA hyperwall. We are grateful to NASA for allowing us this opportunity to participate in their EGU booth.Astronomy Genealogy Project
On May 11, Jennifer Lynn Bartlett, project scientist for astrophysics, will become director of the Astronomy Genealogy Project (AstroGen), which traces academic lineages of astronomers worldwide. Building on earlier collaborations between AstroGen and ADS (now SciX), Jennifer would like to make the full-text of more dissertations findable and accessible through both platforms. Based on the successful Mathematics Genealogy Project, AstroGen is a project of the Historical Astronomy Division of the American Astronomical Society. The current director, Joe Tenn (Sonoma State), who founded the AstroGen in 2013, is retiring on his 85th birthday.Missing Links
We have identified around 1,000 broken links to LPI-hosted content associated with LPSC abstracts, possibly due to targeted removal or other technical issues. If you discover a broken link in your LPI abstract or other scientific publication, please contact us at help@scixplorer.org so we can investigate and, if possible, restore access to the content. -
Development and data holdings updates as of May 1st:
- Website and API
- [new] Replaced
adswswithapi-gatewayas the core API module for ADS and SciX - [improved] Nectar: Moved facet buttons to the side and added view_item event
- [improved] Export: added POST option for a formatted response
- [ops] Nectar: Updated abstract and search page tests, reset-password endpoint, and requirements
- [ops] Export: completed some of incomplete doctypes for AASTeX CLS format
- [ops] Upgraded requirements for the Journals Database
- [ops] Vault service updates on the header
- [ops] Biblib: API gateway changes; Added check for mirrored host when sending emails
- Bumblebee changes:
- [improved] Support for new Gateway API: Updated authentication handling, token formats, and API endpoints to align with ADS’s new Gateway infrastructure.
- [fixed] Code Refactoring: Several fixes related to Sentry detected errors and other general code cleanup
- [ops] Continuous Integration Improvements: Improvements to the CI/CD scripts
- [new] Replaced
- Data holdings and pipelines
- 414k new records, and 3.86M new citations
- Website and API
Development details
April 2025
-
Announcements:
APS Global Physics Summit 2025
Last month, project scientists Michael Kurtz and Jennifer Lynn Bartlett demonstrated the power of SciX to more than 200 physicists. They also presented two posters at this meeting of the American Physical Society, which are now on Zenodo:The SciX physics collection contains over 13 million journal articles, preprints, conference proceedings, and books, making it one of the most comprehensive open-science tools available to physicists world-wide. It boasts over 2.5 million open-access items as well as over 170,000 physics education resources. Our broad support for NASA science includes indexing:
- Physical Review ABCDEFMPRSX
- Physica ABCD
- Journal of Physics ABCDEFG CS
- Physics Letters AB
- Nuclear Physics AB
- Journal of High Energy Physics
In addition, we receive APS meeting abstracts annually; we have already processed the 2024 materials. Taking advantage of SciX enables physicists to find and access the literature and to reuse the software and data they need for 21st century science.
New Blog Post, “From ADS to SciX: What I wish I knew about ADS/SciX during my Ph.D.”
One of our Lead Ambassadors, Manuel Pichardo Marcano, shares his insights as an astronomer transitioning from using ADS to SciX. Discover why Manuel believes SciX is the future for accessing the literature, especially if you’re working in interdisciplinary fields like astrochemistry. Learn about his favorite SciX features and how they can benefit your research! Read Manuel’s full blog post here.2024 ADS Users Group Report
The 2024 ADS Users Group met last December to assess the services ADS provides to the astronomical community and evaluate the progress of SciX. At the end of March, they released their report, which offers strategic advice that will assist us as SciX prepares to exit its beta phase. In particular, the Users Group recommends that ADS:- prioritize SciX development
- raise awareness among astronomers about SciX
- focus AI/ML efforts on data enrichment and discovery
- continue developing chatbot tools accompanied by training materials to ensure appropriate use
The ADS and SciX team thanks the ADS Users Group, especially its chair Matthew J. Graham, for their thoughtful program review. We will implement their recommendations over the rest of this year along with those from the SciX Advisory Board, which is focused on the SciX expansion.
The ADS Users Group meets annually in accordance with its charter. If you are interested in participating in the 2025 meeting, please let the chair or project scientist, Jennifer Lynn Bartlett, know.
-
Development and data holdings updates as of April 1st:
- Website and API
- [new] Blog post: “From ADS to SciX: What I wish I knew about ADS/SciX during my Ph.D.
- [new] 2024 ADSUG report
- Bumblebee changes:
- [improved] Removes unused menu item on abstract page navbar and some general cleanup and refactoring
- [fixed] Bug on classic form so that it handles user-specified default database properly
- Nectar changes:
- [new] Added ability to download word clouds and facet lists for easier data sharing and analysis
- [new] Enabled abstract graphics and made abstract display optional in record feedback
- [new] Introduced public sharing links for libraries to make collaboration easier
- [new] Added Earth Science as a collection option in the feedback form
- [new] Added an export menu to the library section for better data management
- [improved] Quick citation display and restored first-author functionality in the classic form
- [improved] Updated the author list to show affiliations as HTML
- [improved] search behavior, including left arrow key handling and query history updates.
- [improved] Standardized pagination UI for a more consistent experienc
- [improved] Updated footer accessibility link text
- [fixed] bugs in the feedback form and improved overall feedback handling
- [ops] Upgraded internal packages and made general code and test maintenance improvements
- Data holdings and pipelines
- 614k new records, and 2.16M new citations
- Website and API
Development details
- Bumblebee Releases
- Nectar Releases
March 2025
-
Announcements:
New Blog Posts on Literature Searches & Ambassador Workshop
Two new blog posts explore how SciX enhances scientific research through advanced literature search tools and a growing community of engaged researchers.The first post, How Earth and Planetary Science Graduate Students Can Use SciX to Conduct Literature Searches, by SciX Ambassador Yueyi Che, provides graduate students with practical strategies for streamlining their literature review process. Che highlights key SciX features such as keyword searches in abstracts, author filtering, and citation mapping, demonstrating how these tools can improve research efficiency and discovery.
The second post, the 2024 SciX Ambassador Workshop Report, offers an in-depth look at the recent SciX Lead Ambassador Workshop. This gathering brought together researchers from diverse fields to strengthen community connections, develop engagement strategies, and explore new ways to promote SciX. The report highlights the program’s mission, the selection of ambassadors, and key outcomes, including the development of community guidelines and outreach initiatives.
These blog posts underscore SciX’s commitment to supporting researchers with powerful search capabilities and fostering collaboration across disciplines. Read the full articles on the SciX website to learn more about how the platform is transforming scientific research and engagement.
Join the SciX Team: Now Hiring a Community Coordinator
SciX, the next-generation scientific research platform expanding the Astrophysics Data System (ADS), is seeking a dynamic Community Coordinator to help grow and engage its research community. This part-time, remote contract role is offered through ScienceBetter Consulting and provides the opportunity to lead outreach efforts, develop engagement strategies, and support the SciX Ambassador Program—all while connecting scientists with cutting-edge literature search tools.
About the Role: The SciX Community Coordinator will play a key role in user engagement, marketing, and science communication, ensuring that researchers in Astrophysics, Earth Science, Planetary Science, Heliophysics, and NASA-supported Biological & Physical Sciences discover and utilize SciX. Responsibilities include:- Building relationships with researchers and institutions
- Managing social media, newsletters, and blog content
- Organizing workshops and conference participation
- Supporting and growing the SciX Ambassador Program
Who Should Apply? We are looking for a skilled communicator with experience in scientific outreach, community engagement, and digital marketing. Ideal candidates will have connections within NASA’s Science Mission Directorate (SMD) research communities—especially in Earth Sciences—and a passion for advancing open science.
Learn more and apply: SciX Community Coordinator Position
SciX Seeking Heliophysicist for Lead Ambassador Program
SciX has one available spot for a heliophysicist to join our Lead Ambassador Program. We are seeking a heliophysics researcher who is enthusiastic about science communication and community engagement. We especially encourage early career researchers (including graduate students) and members of underrepresented groups in STEM to apply. We accept international applications as well.
About the Role: The SciX Lead Ambassadors play a pivotal role in bridging the gap between SciX and their respective communities. Key highlights of this program include:- Two-year term including monthly online cohort/SciX meetings (must attend at least 4 meetings per year). Time commitment is estimated at 2-8 hours per month.
- Recognition on our SciX website ambassador page and opportunities to showcase your work and community engagement on our blogs.
- A 2.5-day workshop at the Harvard & Smithsonian Center for Astrophysics (TBD in July or August 2025) where you will network with peers, learn community engagement skills, and receive training on the SciX platform to share with your communities.
- Inform strategies to enhance the platform’s reach and benefit for your communities, grow an online space for ambassadors to share resources, connect with the SciX team, and collaborate with peers worldwide.
- Present on SciX in whichever ways are impactful and accessible for you (locally at your institute, virtually at a meeting, in person at a workshop, etc.)
- Travel reimbursement up to $2500 for the workshop and reimbursement up to $2500 to a conference of your choice to present on your work and SciX.
Learn more and apply: SciX Lead Ambassador for Heliophysics
-
Development and data holdings updates as of March 1st:
- Website and API
- [new] Blog posts: Earth Science Literatire Review, and 2024 Ambassador Workshop
- [new] Help page: Additional policy describing Mirror Links
- [improved] Bumblebee changes:
- Changed wording of footer links for accessibility
- Improvements made to loader script to be more robust, in hopes to mitigate module timeouts for some users
- Updated classic form to handle first_author style queries
- General bugfixes and improvements, specifically targeting long-standing errors
- Data holdings and pipelines
- 356.8k new records, and 4.9M new citations
- Website and API
Development details
- Bumblebee Releases
February 2025
-
Announcements:
SciX Chat Assistant
The SciX Team is pleased to introduce three new chatbot assistants designed to enhance your Science Explorer user experience! These AI-powered tools seamlessly integrate with the expanded SciX digital library platform, making it easier than ever to find scientific literature, navigate help resources, and automate API queries.Want to explore the latest research? The SciX Chat Assistant helps you search for papers by topic, author, or keyword, keeping you updated on cutting-edge discoveries across planetary science, astrophysics, heliophysics, and Earth science. Try it out here.
Need guidance on using SciX? The SciX Help Desk Assistant quickly directs you to FAQs, tutorials, and troubleshooting resources, so you can find answers fast. Check it out here.
Looking to streamline your workflow? The SciX Script Generator creates custom scripts for querying the SciX API, perfect for automating searches and integrating SciX data into your projects. Generate your script here.
We invite you to test these new resources and let us know what you think at adshelp@cfa.harvard.edu
Spotlight on SciX Project Scientist Dr. Jennifer Lynn Bartlett
The Women In Astronomy blog recently featured Dr. Jennifer Lynn Bartlett, SciX Project Scientist, in their latest career profile: “Have Sextant, Will Travel.”In this insightful piece, Dr. Bartlett shares her career journey, from navigating the worlds of astrometry and timekeeping to her current work advancing research accessibility with SciX. Her story highlights the importance of interdisciplinary expertise, adaptability, and a passion for both historical and cutting-edge science.
Read the full post to learn more about Dr. Bartlett’s path and her contributions to the astronomical community!
Now Available: SciX Posters from the AAS Winter Meeting
Missed the SciX presentations at the American Astronomical Society’s (AAS) winter meeting? You can now explore the posters online!SciX contributed to several engaging sessions, sharing insights into project management, public outreach for solar eclipses, and innovations in astronomy education. SciX iposters from the meeting include:
- “What if it Rains on Your Eclipse: Planning Ahead for August 2045“ – A look at strategies for public engagement and observational planning for future eclipses.
- “Beyond Astronomy Content: Communication Skills for All Our Students“ – Exploring the role of communication skills in astronomy education and career development.
- “Astro-3: Restoring Space Astronomy Flight Hardware for Public Education“ – Showcasing the Astro Restoration Project’s efforts to preserve and restore the SpaceLab Astro science payload, creating the largest flown space science observatory available for public display to inspire future generations in STEM.
- “ADS and SciX: Pioneering the Next Generation of Interdisciplinary Research Discover“ – Highlighting how SciX builds on the Astrophysics Data System (ADS) to create a unified, AI-powered platform integrating literature, data, and software across NASA’s Science Mission Directorate, supporting open science and interdisciplinary research.
- “Science Explorer: Not Your Adviser’s ADS“ – A look at how SciX expands the Astrophysics Data System (ADS) with AI-powered tools, semantic search, and interdisciplinary connections to enhance scientific discovery.
Thank you to everyone who joined us at AAS—we look forward to seeing you again soon!
-
Development and data holdings updates as of February 1st:
- Website and API
- [improved] Help pages: updated permalinks to have trailing forward slashes
- Nectar changes include:
- [improved] Updated abstract metadata in UI to support UAT implementation; added UAT keywords to abstract page, and UAT facet + [improved] Added bulk citation fetching in the export interface
- [fixed] html in abstract metadata
- [fixed] ‘Query Canceled’ error behavior
- [ops] Updated login step to show message about needing to reset password
- [ops] Updated packages for code formatting and system monitoring
- [ops] Gateway and dependency upgrades
- [fixed] Oracle: bug where a bibcode match was returned if either the ‘source’ or ‘match’ bibcode matched the computed one. Now only ‘source’ is returned if matched.
- Data holdings and pipelines
- 106.6k new records, and 8M new citations
- Website and API
Development details
January 2025
- Announcements:
-
SciX at the 2025 AAS Winter Meeting
The American Astronomical Society’s (AAS) winter meeting will take place in National Harbor, MD, from January 12-16, 2025, and SciX is pleased to contribute to this important event. With a variety of panels, presentations, and demonstrations, SciX will share insights and tools aimed at advancing astronomical research, education, and outreach.Sunday, January 12: SciX’s Jennifer Lynn Bartlett will participate as a panelist in the “Effective Project Management for Everyone: How to Get Things Done” conference workshop (8:00 AM - 12:00 PM) in Chesapeake D/E supported by the AAS Committee on Employment. Later that day, Bartlett will lead the annual meeting of the Working Group on the Preservation of Astronomical Heritage (5:30-6:30 PM) in Chesapeake A/B. This session will focus on strategies for preserving astronomical structures, instruments, and records for future research and public engagement.
Monday, January 13: An ADS/SciX demo at the NASA Exhibit Hall Booth High Top Table 2 from 9:00 - 11:00 AM as well as a presentation by Bartlett and Malynda R. Chizek Frouard, titled “What if it Rains on Your Eclipse: Planning Ahead for August 2045” (9:00-10:00 AM). This iPoster session will take place in the Prince George Exhibit Hall at Terminal 50 and will explore public outreach strategies and observational projects for future solar eclipses. That evening, Bartlett and collaborators will present the iPoster “Beyond Astronomy Content: Communication Skills for All Our Students” (5:30-6:30 PM) at Terminal 140 in the Prince George’s Pre-Function Room CD. This session will discuss integrating communication skills into astronomy education to benefit students’ learning and career readiness.
Tuesday, January 14: SciX staff will host office hours as part of the AAS Working Group on the Unified Astronomy Thesaurus (UAT) at Table 3 in the Exhibit Hall at AAS Booth #325 from 9:00-10:00 AM. Bartlett and colleagues will answer questions about using the UAT and how it can support researchers, educators, and publishers.
Wednesday, January 15: NASA Hyperwall Talk at Booth 505 at 9:45 AM, where Alberto Accomazzi will present “Science Explorer: Accelerating the Discovery of NASA Science.” Later that day, Jennifer Lynn Bartlett, Kelly Lockhart, and SciX Ambassador Manuel Pichardo Marcano will present “Not Your Advisor’s ADS” (5:30-6:00 PM) at the Exhibitor Theater (Booth #533), highlighting the modern capabilities of the Astrophysics Data System (ADS).
Thursday, January 16: SciX Ambassador Manuel Pichardo Marcano will present his talk “Seeing the Most Massive White Dwarf Mergers with LILA” (10:40-10:50 AM). An ADS/SciX Demo will take place at High Top Table 1 in the NASA Booth from 9:00-11:00 AM. Bartlett will also present “ADS and SciX: Pioneering the Next Generation of Interdisciplinary Research Discovery” in the Potomac Room 5-6 (2:30-2:40 PM) as part of Session 442: Technology Developments in Outreach, Education, and Research.
In addition to the busy schedule of events at the AAS meeting, the ADS/SciX team will be available all week at the Center for Astrophysics Booth #705 to answer questions, provide demonstrations, and discuss tools and resources. Concurrently, ADS/SciX staff will also be exhibiting at Booth #545 for the American Meteorological Society meeting (12-16 Jan in New Orleans, LA), further showcasing SciX’s interdisciplinary contributions to scientific research and education.
We look forward to engaging with the scientific community at these upcoming events! For further details, we invite you to visit the respective event links or stop by our booth locations at each conference.
-
- Development and data holdings updates as of January 1st:
- Website and API
- [new] Added SciX Handouts to Help pages
- [new] Export Service: Set a default for authors to 200, and added three new export formats:
agu,gsa,ams - [improved] Added ‘What’s New’ to SciX Help pages
- [improved] Journals Database: added new
/browse/<bibstem>endpoint which provides a simpler output than the/summaryendpoint - Bumblebee changes:
- [new] added ‘Duplicate’ as an option for the Associated Articles Feedback Form
- [improved] Updates to autocomplete and quickfields to make first author queries use the
first_author:""syntax instead ofauthor:"^" - [fixed] ORCiD deletion, token refreshing, missing related materials section, and ORCiD profiles with undefined last name
- [ops] Updates to the API Gateway, bearer strings, login fields, item-view events and analytics improvements, expiration reformat, email changing, authentication, email verifications, sentry sdk setup, and dark mode text contrast
- Solr changes:
- [new] Schema additions with Planetary Names fields, UAT fields, two new fields, and added renamed versions of the gpn family of fields as part of their deprecation
- [improved] Implemented negative positional field search
- [ops] Completed a major infrastructure overhaul to bring the codebase from Solr 7 to Solr 9
- Introducing Nectar as our SciX server-side rendering:
- [new] Added SciX carousel
- [improved] Replaced
gpn_idwithplanetary_feature_id, updated planetary facet fields, and one click export - [improved] Allow facet author searches to have lowercase initial letter
- [improved] Allow URL and DOI for related papers in the Associated Articles Feedback Form
- [fixed] Visualization issue, highlights toggle, and change first author fields added from autocomplete or quick fields to use the
first_author:""syntax instead ofauthor:"^" - [ops] Updates on barrels, eslint speed and action runners, volume content menu, analytics improvements, upgrade Sentry, updated journals
/summaryendpoint
- Data holdings and pipelines
- 450k new records, and 13.9M new citations
- Website and API
Development details
- Bumblebee Releases
- Export Service Releases
- Journals Database Releases
- Nectar Releases
- Oracle Service Releases
- Solr Releases
December 2024
-
Announcements:
-
ADS/SciX at Upcoming Conferences
The ADS/SciX team is gearing up for an exciting season of outreach and engagement at some of the most prominent Earth and space science conferences. We look forward to connecting with researchers, educators, and stakeholders to showcase how our digital library portal supports open science and accelerates discoveries.-
American Geophysical Union (AGU) Fall Meeting
The AGU Fall Meeting is one of the largest international gatherings in the Earth and space sciences. Here’s your guide to engaging with the ADS/SciX team throughout the week:- Sunday, 8 December
08:30 AM - 12:00 PM Workshop: Harnessing the Power of NASA Open Digital Repositories for Earth and Space Research Workshop Co-Hosts: Science Explorer (SciX), NASA Science Discovery Engine, & the Planetary Data System Location: Marriott Marquis, Independence F-H . (Registration for this event is now closed) - Monday, 9 December
8:30 AM - 12:30 PM Poster Session - Progress and Impact of Continental and Regional-Scale Magnetotelluric Arrays Chair: Anna Kelbert Location: Poster Hall (Geomagnetism, Paleomagnetism & Electromagnitism, GP11B) 10:20 AM - 11:50 PM Oral Session - Streamlining and Improving Publication Transparency in the Natural Sciences Presenter: Alberto Accomazzi Location: Ballroom B (Convention Center) 1:40 PM - 5:30 PM Poster Session - Bridging Disciplines and Advancing Discovery in Earth and Space Sciences through the NASA Science Explorer Presenter: Stephanie Jarmak Location: Poster Hall (Informatics, IN13A-2155) 3:00 PM - 6:00 PM Visit us at the NASA Booth & SciX Booth (#850) in the Exhibit Hall - Tuesday, 10 December
8:30 AM - 10:00 AM Oral Session - Progress and Impact of Continental and Regional-Scale Magnetotelluric Arrays Chair: Anna Kelbert Location: Convention Center Room 202B 8:30 AM - 12:20 PM Poster Session - Science Explorer (SciX): A Valuable New Information Service for Earth Science Literature, Data, and Software Discovery Presenter: Anna Kelbert, Alberto Accomazzi, & Yueyi Che Location: Poster Hall, Informatics, IN21C-2171 10:00 AM - 12:00 PM SciX Demos at the ESIP Data Help Desk Presenter: Carolyn Grant Exhibit Hall 2:10 PM - 3:00 PM Oral Presentation - Quantifying Hydration Abundance and Distribution on Asteroid (16) Psyche with JWST Data Presenter: Stephanie Jarmak Location: Marriott Marquis Liberty M 10:00 AM - 6:00 PM Visit us at the NASA Booth & SciX Booth (#850) in the Exhibit Hall -
Wednesday, 11 December
10:00 AM - 6:00 PM Visit us at the NASA Booth & SciX Booth (#850) in the Exhibit Hall -
Thursday, 12 December
10:00 AM - 12:00 PM SciX Demo at the ESIP Data Help Desk Presenter: Anna Kelbert Exhibit Hall 10:00 AM - 1:00 PM Visit us at the NASA Booth & SciX Booth (#850) in the Exhibit Hall -
Friday, 13 December
8:30 AM - 12:30 PM Poster Session - Science Explorer (SciX): Accelerating Discovery Across NASA Data, Software, & Science Presenter: Jennifer Lynn Bartlett Location: Hall B-C (Convention Center Poster Hall) -
Looking Ahead: January 2025, ADS/SciX will exhibit and present at the following:
- American Astronomical Society Meeting (12–16 January) in National Harbor, MD
- American Meteorological Society Meeting (12–16 January) in New Orleans, LA
These events will feature live demos, new resources for researchers, and opportunities to engage with our tools. Don’t miss the chance to see how ADS/SciX can support your scientific endeavors. For more details, visit the respective event links or stop by our booth at AGU. We can’t wait to see you there! -
-
Dr. Stephanie Jarmak Elected as AGU Informatics Secretary
We are thrilled to announce that Dr. Stephanie Jarmak, SciX’s Planetary Science Project Scientist, has been elected as the Informatics Secretary for the American Geophysical Union’s (AGU) Informatics Section. Dr. Jarmak will begin her two-year term on 1 January 2025. As Informatics Secretary, Dr. Jarmak will play a vital role in supporting the section’s mission to transform data systems into knowledge systems, enhancing the capabilities of Earth and space science research. The AGU Informatics Section focuses on critical topics like data management and analysis, large-scale computational experimentation, and the hardware and software infrastructure essential to advancing Earth and space science. View the full election announcement here.
-
-
Development and data holdings updates as of December 1st:
- Website and API
- [new] About pages: created and updated the December 2024 ADSUG Program
- [improved] About pages: Updated ADSUG members and added headshots for ADS Users Group
- [improved] About pages: added 2023 ADSUG presentations
- [improved] Help pages: Updated positional field search documentation to include description of last author/negative position searches with examples
- [improved] Journals Database: added support to store a canonical abbreviation for each journal
- [improved] Vault: fixed logs and removed bibcode sort
- Data holdings and pipelines
- 401k new records, and 10.9M new citations
- Website and API
November 2024
- Announcements:
- SciX Activities at the American Geophysical Union (AGU) 2024 Fall Meeting
The Science Explorer (SciX) and Astrophysics Data System (ADS) team will be participating in the AGU Fall Meeting in Washington, D.C., from December 8–13. This event is a great opportunity for researchers to explore tools and resources for open-access Earth and space science. We invite you to join our co-hosted workshop on Sunday, December 8, titled “Harnessing the Power of NASA Open Digital Repositories for Earth and Space Research,” which will be co-hosted with the Planetary Data System (PDS) and the NASA Science Discovery Engine. This hands-on session will provide an in-depth look at how SciX and ADS support data discovery and integration. You can also connect with our teams at Booth #850 in the Exhibit Hall. Our team will be available to discuss SciX, ADS, and how these platforms can assist in advancing Earth and space science research.
SciX Schedule Highlights at AGU:- Sunday, 8 December, 8:30 - 12:00 PM | Marriott Marquis Room Independence F-H
Pre-Meeting Workshop: Harnessing the Power of NASA Open Digital Repositories for Earth and Space Research (Registration required via the AGU meeting registration system). - Monday, 9 December, 1:40 PM - 5:30 PM
Poster Presentation by Dr. Stephanie Jarmak: Bridging Disciplines and Advancing Discovery in Earth and Space Sciences through the NASA Science Explorer - Tuesday, 10 December 8:30 AM - 12:30 PM
Poster Presentation by Dr. Anna Kelbert: Science Explorer (SciX): A Valuable New Information Service for Earth Science Literature, Data, and Software Discovery - Friday, 13 December 8:30 AM - 12:30 PM
Poster Presentation by Dr. Jennifer Lynn Bartlett: Science Explorer (SciX): Accelerating Discovery Across NASA Data, Software, & Science
- Sunday, 8 December, 8:30 - 12:00 PM | Marriott Marquis Room Independence F-H
- ADS/SciX Shares AI and ML Innovations with NASA’s Digital Transformation Team
Dr. Kelly Lockhart, the Technical Lead for the Astrophysics Data System (ADS) and Science Explorer (SciX), recently presented the ADS/SciX project to NASA’s Digital Transformation Team. This agency-level initiative was created by NASA to improve competitiveness in a digital-first workplace, enhance resource efficiency, and address increasing digital security concerns. In the presentation, Dr. Lockhart highlighted how the ADS/SciX project is using artificial intelligence (AI) and machine learning (ML) to enhance research accessibility and streamline the discovery process across scientific disciplines. These efforts align with NASA’s strategic goals for digital transformation by supporting efficient data management and expanding research potential. - New Publication: INDUS – A Language Model for Scientific Research Applications
Members of the ADS/SciX Team recently co-authored a pre-print publication titled “INDUS: Effective and Efficient Language Models for Scientific Applications.” This paper introduces INDUS, a specialized language model designed to enhance the efficiency and accuracy of scientific text analysis. Developed to handle complex language and large datasets, INDUS aims to streamline research processes across various scientific fields. To read the abstract or download the full text pre-print, visit SciX here. For a concise overview of the paper’s main points, a video summary is also available on the Paper with Video YouTube channel, which covers INDUS’s core concepts and intended applications in a straightforward format. There’s also an active discussion on Discord, where researchers and viewers can ask questions, share perspectives, and provide feedback on both the paper and the video summary.
- SciX Activities at the American Geophysical Union (AGU) 2024 Fall Meeting
- Development and data holdings updates as of November 1st:
- Website and API
- [new] About pages: Added Paul Di Re to Team page
- [new] About pages: Added Anna Kelbert to Team page
- [fixed] Build issue with setup-ruby
- Data holdings and pipelines
- 378k new records, and 5.5M new citations
- Website and API
Development details
- No changes
October 2024
- Announcements:
- Help Us Improve ADS: Complete Our User Survey by 1 November
Are you a user of the Astrophysics Data System (ADS)? We invite you to share your valuable feedback by completing a user survey. Your insights will help us refine the platform to better meet your research and open science needs. The survey will take approximately 10 minutes to complete. As a token of our appreciation, those who submit responses by 1 November 2024 will have the chance to enter a drawing for a SciX T-Shirt. Complete the survey here. - SciX Team Engagement Highlights
The SciX team has been active in various community engagement events. Dr. Stephanie Jarmak recently gave a colloquium talk at the Center for Astrophysics on “Observing Asteroids with JWST,” sharing insights into her planetary science research. You can watch the full presentation here. Dr. Alberto Accomazzi and Dr. Kelly Lockhart participated in the Natural Language Processing (NLP) for Space Science Workshop, held at the European Space Astronomy Center (ESAC) in Madrid. Their talk on “AI and NLP in ADS” is available here. The event explored the growing role of NLP and large language models in space sciences, followed by hands-on hack days. Dr. Mugdha Polimera also attended the NLP workshop and contributed to a hack project that resulted in a chat bot that can answer questions about published astronomy softwares and packages (check out the app here). Additionally, Dr. Jennifer Lynn Bartlett presented a SciX colloquium at New Mexico Tech. Her slides are accessible here.
Lastly, the SciX team is gearing up for the AAS Division for Planetary Sciences meeting in Boise, ID (6-10 October). If you’re attending, visit the SciX booth to connect with the team! - Registration Now Open for the SciX Workshop the AGU Fall Meeting
If you’re attending the American Geophysical Union (AGU) Fall Meeting in Washington, DC, don’t forget to sign up for the pre-meeting workshop co-hosted by Science Explorer (SciX), the Planetary Data System, and NASA Science Discovery Engine. The workshop will take place on Sunday, December 8, 2024, from 08:30 AM to 12:00 PM in Room Independence F-H at the Marriott Marquis hotel. The ticketed event title is (PREWS4). To participate, please add this workshop as a ticketed event when registering for the AGU meeting. You can find more details about the workshop here. The last day to register for AGU at the Early Bird rate is November 6, 2024. Be sure to secure your spot!
- Help Us Improve ADS: Complete Our User Survey by 1 November
- Development and data holdings updates as of October 1st:
- Website and API
- [improved] Updated the search syntax help page list of bibgroups
- [fixed] Export: fixed output issues with formatting errors - bug in custom csv output, IEEE and Icarus
eid, and JATsXMLpub-date - [fixed] ORCID: set putcodes back to ints to fix bug with deleting claims
- [ops] Export: Updated cls formats to output
volumeandpagefor doctype abstract ofaastex, aspc, mnras, and soph formats.
- Data holdings and pipelines
- 406k new records, and 6.88M new citations
- Website and API
Development details
September 2024
- Announcements:
- We’ve reached 8 million records in the SciX Earth Science collection! Explore recent papers here.
-
Workshop Convenes SciX Ambassadors at the Harvard-Smithsonian Center for Astrophysics
The inaugural Science Explorer (SciX) Ambassador workshop took place 20-23 August at the Harvard-Smithsonian Center for Astrophysics in Cambridge, MA. This milestone event brought together the first group of SciX Ambassadors—scientific experts and outreach professionals from around the world—marking their first meeting as a unified team. The workshop focused on advancing SciX’s mission of fostering open science and accelerating discovery in NASA Science Mission Directorate areas, including Astrophysics, Planetary Science, Heliophysics, Earth Science, and Physical & Biological Sciences.
Over the four-day event, the new SciX Ambassadors collaborated on strategies to enhance access to scientific resources and promote interdisciplinary collaboration through SciX’s digital library platform. The workshop was designed to empower these pioneering Ambassadors to assume leadership roles in their communities, advocating for open access to scientific literature, data, and tools. Participants meet with the SciX development team to learn more about the platform and craft personalized work plans to guide their future activities within the Ambassador program.
Learn more about the SciX Ambassadors here. -
SciX Training Workshop at AGU Fall Meeting
The Science Explorer (SciX) is pleased to announce an in-person workshop, “Harnessing the Power of NASA Open Digital Repositories for Earth and Space Research,” scheduled for Sunday, December 8 in Washington, DC. This event is part of the pre-conference workshop program for the American Geophysical Union (AGU) Fall Meeting. The 3-hour session will equip researchers with essential skills to utilize NASA’s digital resources, enhancing their ability to access and integrate Earth and space data effectively.
Aligned with the AGU conference theme, “What’s Next for Science,” the workshop will delve into open digital repositories for NASA’s research, including SciX, the Planetary Data System, and the NASA Science Discovery Engine. Participants will engage in hands-on demonstrations and guided exercises, learning to navigate these platforms for comprehensive data discovery and integration. Emphasizing the importance of interdisciplinary collaboration, the workshop aims to bridge gaps between scientific disciplines and geographic boundaries, promoting innovative research and fostering a culture of openness and transparency.
Please save the date and plan to register for the workshop when you sign up for the AGU Fall Meeting later this fall! -
Careers at ADS/SciX - We are now hiring for the following two positions on the ADS/SciX team:
Digital Technologies Development Librarian: The ADS/SciX team is seeking a Digital Technologies Development Librarian who will support the team by designing and implementing new tools, technology and services, and will be involved in collection management, assisting with content decisions, documentation and user support.
Applications are due by September 27. Apply here.
IT Specialist (Back Office Developer): The ADS/SciX team is seeking an IT Specialist (Back Office Developer). The position requires experience with search engines (e.g., Solr, Elasticsearch), designing and building software (Java and Python), data pipelines, and REST APIs.
Key responsibilities include maintaining and enhancing the ADS search engine (Java), managing its public API (Python), improving text processing pipelines (Python), and developing new functionality for metadata enhancement, citation analysis, and recommendations. The role will utilize ADS’s natural language processing, machine learning, and deep learning technologies.
Applications are due by September 30. Apply here. - ADS/SciX Staff to Attend NLP Workshop in Space Sciences
Staff members from the Astrophysics Data System (ADS) and Science Explorer (SciX) will be participating in the upcoming workshop on Natural Language Processing (NLP) in the Space Sciences. This workshop will focus on applying NLP techniques to improve data analysis and knowledge discovery in space science research. Our participation reflects our ongoing efforts to stay informed about and contribute to advancements in technology relevant to our digital resources. Learn more about the workshop here.
- Development and data holdings updates as of September 1st:
- Website and API
- [new] Help pages: Descriptions of bibgroups
- [ops] Citation helper and Object service: Image rebuild and dependency updates
- [ops] Help pages: Switched to using Bundler for module install/management
- [ops] Help pages: Added a few plugins to improve SEO, including a plugin to generate sitemaps
- [ops] Help pages: Changed from GitHub pages deployment to using GitHub actions so that restricted plugins can be used
- Data holdings and pipelines
- 222K new records, and 12.6M new citations
- Website and API
August 2024
- Announcements:
-
Job Opening: IT Specialist (Back Office Developer) on the ADS/SciX Team
The ADS/SciX team is seeking an IT Specialist (Back Office Developer). The position requires experience with search engines (e.g., Solr, Elasticsearch), designing and building software (Java and Python), data pipelines, and REST APIs.
Key responsibilities include maintaining and enhancing the ADS search engine (Java), managing its public API (Python), improving text processing pipelines (Python), and developing new functionality for metadata enhancement, citation analysis, and recommendations. The role will utilize ADS’s natural language processing, machine learning, and deep learning technologies. Applications are due by September 30. Apply here. -
Final Blog Post in SciX Data Linking and Indexing Series by Edwin Henneken
The final installment in Edwin Henneken’s three-part blog series for SciX is now available. This concluding post offers an insightful exploration into the advanced processes of data linking and indexing within the Science Explorer. We invite you to check out the entire 3-part series below.
Part I: Data Holdings
This post explains how SciX integrates literature with research data, software, and services. It describes how data is represented within SciX, using a graph of digital objects and their relationships to illustrate the system’s structure. This sets the foundation for understanding the data linking mechanisms that support the FAIR principles in physical sciences.
Part II: Linked Data
The second post discusses linked data within the Research Life Cycle framework. It highlights the importance of linking digital artifacts like data and software to scholarly articles. The post also covers the process of capturing and indexing citations to these research products and provides strategies for finding linked data within SciX.
Part III: Cited Data
This final part explains how SciX manages cited data products. There is no fundamental difference between articles citing other articles, and articles citing data. Citations are just one small subset of the entire graph of linkages between research assets. -
Video Spotlight
On 17 July, Dr. Alberto Accomazzi, Principal Investigator of the Astrophysics Data System and the Science Explorer, presented a lecture at the Johns Hopkins Center for Language and Speech Processing (CLSP). His talk, “The NASA Astrophysics Data System: A Case Study in the Integration of AI and Digital Libraries,” explored the evolution and future of the ADS, focusing on the integration of AI techniques. The lecture is now available for viewing here on the CLSP YouTube channel.
-
- Development and data holdings updates as of August 1st:
- Website and API
- [ops] Updated paths and footer for Resolver Gateway Service
- [ops] Vis updates: Migrated from Python 2 to Python 3, resulting bug fixes to the
round()function, and modified paper and author networks - [ops] Bumblebee updates: Updated footer logos, feedback forms, and modified item-view event, making separate events for each collection found with the
categoryfield being updated
- Data holdings and pipelines
- 341.3K new records, and 1.89M new citations
- Website and API
Development details
- Bumblebee Releases
- Resolver Gateway Releases
- Vis Service Releases
July 2024
-
Announcements:
- New Blog Series: SciX Data Linking and Indexing: We are pleased to share the first two installments in a new blog series by Edwin Henneken, SciX’s Content, Curation & Collaborations Lead. These posts provide an informative look into the processes of data linking and indexing within Science Explorer (SciX).
- Part I: Data Holdings
This post explains how SciX integrates literature with research data, software, and services. It describes how data is represented within SciX, using a graph of digital objects and their relationships to illustrate the system’s structure. This sets the foundation for understanding the data linking mechanisms that support the FAIR principles in physical sciences. - Part II: Linked Data
The second post discusses linked data within the Research Life Cycle framework. It highlights the importance of linking digital artifacts like data and software to scholarly articles. The post also covers the process of capturing and indexing citations to these research products and provides strategies for finding linked data within SciX.
- Part I: Data Holdings
- Upcoming Conferences and Events: Please be on the lookout for members of the SciX team as well as our new cohort of SciX Ambassadors at the following events in July!
- Visit the SciX Booth at the Special Library Association Annual Conference in Kingston, RI from July 13-16.
- Watch SciX project staff present at the Incorporating Data Science and Open Science in Aquatic Research Summit taking place online 18-19 July.
- Connect with SciX Ambassador Chenyue Jiao at the Earth Science Information Partners (ESIP) meeting in Asheville, NC and online from July 23-26.
- New Blog Series: SciX Data Linking and Indexing: We are pleased to share the first two installments in a new blog series by Edwin Henneken, SciX’s Content, Curation & Collaborations Lead. These posts provide an informative look into the processes of data linking and indexing within Science Explorer (SciX).
-
Development and data holdings updates as of July 1st:
- Website and API
- [new] Data Linking and Indexing blog series
- [fixed] Several broken links on various help pages
- [ops] Journals database maintenance updates for exporting data (ISSN identifiers, refereed conference proceedings pubtype), deleting bibstems, and some bug fixes
- Data holdings and pipelines
- 86k new records, 3.06M new citations
- Website and API
June 2024
- Announcements:
-
We are pleased to announce that our Earth Science collection now contains over 7.5 million records. We have finished ingesting back content for Elsevier journals and are preparing to load content from Springer, Wiley, Taylor and Francis, and other relevant publishers.
-
New Blog: Historic Observatory Publications in the Science Explorer - Discover the rich legacy of historic scientific publications now available through the Science Explorer (SciX). Foundational archives, including work from renowned observatories, have been meticulously digitized and are accessible to all. Dive into our full blog post here to learn more about these invaluable records and how you might also contribute to preserving the history of science.
-
Upcoming Conferences & Events Featuring SciX & ADS - In June, the SciX team is looking forward to connecting with our user community at the American Astronomical Society (AAS) 244th Meeting (9-13 June, Madison, WI) and the American Libraries Association 2024 Annual Conference (27 June-2 July, San Diego, CA) where our staff will be based at the NASA Booth #1939. If you are attending the #AAS224 Meeting, don’t forget to visit us at the Smithsonian Astrophysical Data System Booth in the exhibit hall or to join us for the following poster presentations and special session:
-
Historic Observatory Publications in the Astrophysics Data System
Authors: Jennifer Bartlett, Donna Thompson, the Astrophysics Data System (ADS) Team
iPoster Session: 107.02 History iPoster, Terminal #27
Date & Time: Monday, 10 June from 9-10am CT
Location: Monona Terrace Convention Center Exhibit Hall AThis iPoster highlights the efforts of Science Explorer (SciX) in digitizing and preserving historic observatory publications. It emphasizes the importance of these documents, which contain foundational astronomical research and unique observational data, and outlines the process and criteria for including new materials in the archive. The poster also discusses the expansion of ADS to include planetary science, heliophysics, and earth science, while maintaining its commitment to the astronomy and astrophysics communities.
-
Historic Observatories: Don’t Forget the Data!
Authors: James Lattis, University of Wisconsin, Madison; R. Elizabeth Griffin, Herzberg Astronomy & Astrophysics Research Centre; Wayne Osborn, Central Michigan University; Jennifer Bartlett, NASA/SAO ADS (SciX)
iPoster Session: 107.02 History iPoster, Terminal #26
Date & Time: Monday, 10 June from 9-10am CT
Location: Monona Terrace Convention Center Exhibit Hall AThis poster emphasizes the critical importance of preserving the observational data produced by historic observatories, particularly photographic plates, which contain invaluable records of astronomical objects and events from the past. Despite technological advancements rendering some observatories’ practices outdated, these plates provide unique information that modern detectors cannot capture, crucial for understanding long-term changes in astrophysics. The poster calls for urgent efforts to preserve these delicate and bulky historical data alongside their metadata to prevent their loss.
-
Historic Observatories: Current Activities and Potential for Education, Public Outreach, and Research (Special Session)
Date & Time: Wednesday, 12 June, 2-3:30pm CT
Location: Monona Terrace Convention Center Meeting Rooms KL
Session Presentations and Full Abstract
The presentations in this session will explore the evolving roles of historic observatories in the modern astronomical community and discuss how these older research observatories, while largely outdated in terms of scientific capacities, still hold significance in today’s context. Talks from specific active historic observatories will highlight their missions, education programs, public outreach initiatives, and ongoing research, fostering discussions about their uncertain futures and enduring relevance.
-
-
- Development and data holdings updates as of June 1st:
- Website and API
- [new] Blog post: Historic Observatory Publications in the Science Explorer
- [new] Help pages: Documentation added to describe requirements for our historic literature scanning service, Technical Standards for Scanning Legacy Literature
- [new] Team photo added to our About page
- [fixed] Biblib service: timestamps and sorting bugs
- Data holdings and pipelines
- 1.25M new records, 250k new citations
- Website and API
May 2024
- Announcements:
-
We are extremely pleased to introduce our very first cohort of SciX Ambassadors! These exceptional individuals, representing diverse research disciplines, will play an important role in expanding the reach and impact of SciX by serving as liaisons between the platform and their communities. Through their work, they will enhance the interdisciplinary spirit of SciX and work with us to advance the cause of open science. Learn more about each of the new SciX Ambassadors here.
-
SciX team members will attend the 2024 Astrobiology Science Conference (#AbSciCon24) from May 5-10 in Providence, RI. If you’ll be there, we invite you to stop by our booth in the exhibit hall to meet our Astrophysics Project Scientist, Dr. Jennifer Lynn Bartlett, and Data Curation Librarian, Donna Thompson. We’ll be at booth #5, providing demonstrations of the latest features of the SciX platform. The exhibit hall is open Monday through Wednesday from 9:30–11:30 am and 1–6 pm and we hope you’ll stop by to say hello and explore SciX’s newest capabilities.
-
At the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation happening later this month (20-25 May), you will also find SciX Machine Learning and Natural Language Processing Specialist, Dr. Felix Grezes, and former ADS visiting PhD student, Atilla Kaan Alkan, presenting their paper “Enriching a Time-Domain Astrophysics Corpus with Named Entity Conference and Astrophysical Relationship Annotations”. If you can’t attend the talk or just want to know more about their work, we invite you to explore other publications by Felix and Attila that we’ve pulled together in this open SciX library collection.
-
- Development and data holdings updates as of May 1st:
- Website and API
- [new] Help pages: Added
publisher(pb) to list of custom export formats - [new] Added our ADASS software award to list of awards
- [ops] Export service:
- Modified
conference locationfield to be recognized more inclusively - Updated XML schemas; Moved
publisherbetweenoriginandcopyright, removed url for valid xml, and fixed xml reference to point to correct schema location
- Modified
- [new] Help pages: Added
- Data holdings and pipelines
- 95k new records, 1.04M new citations
- Website and API
April 2024
- Announcements:
-
ADS Users Group Report
We are pleased to announce the publication of the report from the ADS Users Group (ADSUG) meeting held on November 16-17, 2023. The ADSUG serves as an advisory body to the Astrophysics Data System (ADS), offering insights and recommendations to enhance its services and operations.
The report explores the ADS’s role in astronomy research, its potential for AI advancements, and acknowledges the ADS team’s commitment to excellence during the transition to SciX, backed by positive user survey feedback. Key insights include the need for clearer prioritization of work and adapting the ADSUG to reflect diverse user communities. Recommendations for the new user interface and practical suggestions from community feedback are also highlighted.
The full report provides valuable insights and recommendations for enhancing the ADS’s services and operations, ensuring its continued support for the astronomy research community. Access the complete ADSUG report here.
We extend our gratitude to the ADS Users Group for their dedication and contributions to improving the ADS platform. -
SciX Ambassador Program - Last Day to Apply April 4th!
Applications for the SciX Ambassador Program close on April 4th! Don’t miss this opportunity to represent the SciX user community and engage with researchers across various disciplines within NASA’s Science Mission Directorate.
Ambassadors will play a crucial role in fostering connections, expanding access to the SciX digital library, and driving discussions to advance open science. In return, they’ll receive community outreach training, visibility, recognition, and financial support for in-person trainings and conferences.
Apply now and become a leader in the SciX community! Learn more and submit your application here. -
SciX Conference Participation
The SciX team delivered three presentations at the recent Year of Open Science (YOS) Culminating Conference- The Science Explorer: ADS for all of NASA Science by Alberto Accomazzi
- Promoting FAIRness via Metadata Enrichment in the Science Explorer by Alberto Accomazzi
- User Engagement in the Science Explorer (SciX) Open Science Initiative by Jennifer Lynn Bartlett and Stephanie Jarmak
If you registered for the online event, you can access session recordings through April 21st.
Also, don’t forget to save the date for SciX’s booth at the upcoming AbSciCon conference from May 5-10 in Providence, RI. If you’re planning to attend, we’d love to connect with you.
-
- Development and data holdings updates as of April 1st:
- Website and API
- [new] Blog: SciX Ambassadors
- [improved] Updated help page for the score sort method
- [fixed] Fixed myADS bug where data gets lost when notification is deactivated
- [ops] Maintenance on the Bearer Token for ORCID
- Data holdings and pipelines
- 334k new records, 2.58M new citations
- Website and API
March 2024
- Announcements:
-
Applications Now Being Accepted for the SciX Ambassador Program - Ambassadors will serve as SciX user community representatives, actively engaging with the scientific community across various disciplines within NASA’s Science Mission Directorate. They will work with the SciX team to foster connections among researchers in fields such as Astrophysics, Earth Science, Planetary Science, Heliophysics, and Biological & Physical Sciences. As communicators, ambassadors will convey information about the SciX digital library resource, expanding SciX access and impact for new audiences. Their leadership will drive discussions, organize events, and provide mentorship to fellow researchers, contributing to the advancement of open science. In recognition of their contributions, ambassadors will receive community outreach training, visibility and recognition for their contributions as a SciX community leader, and financial support to attend in-person trainings at the Harvard & Smithsonian Center for Astrophysics and other conferences where they will present on SciX and their research. We invite you to learn more about the program and apply here by 4 April 2024.
-
SciX Team Presentations at the Year of Open Science Online Conference - Please join members of the SciX team at the upcoming Year of Open Science (YOS) Culminating Conference taking place online March 21 and 22, 2024. Hosted by the Center for Open Science in collaboration with NASA, this free event will showcase outcomes, coalition-building efforts, and ongoing work stemming from the 2023 Year of Open Science (YOS). Learn more and register here.
-
New Blog Post! Highlights the Role of User Feedback in the ADS to SciX Expansion - The crucial role of user feedback in shaping the evolution of both ADS and the Science Explorer (SciX) is the focus of a new blog post. Explore how your input is driving enhancements to search functionality and ensuring a positive transition from ADS to the expanded SciX platform here.
-
Assessing your Observatory’s Impact: Best Practices in Establishing and Maintaining Observatory Bibliographies - A new publication from the Observatory Bibliographers Collaboration features the use of the Astrophysics Data System as a best practice in establishing and maintaining bibliographies for observatories wishing to measure and evaluate the scientific output and overall impact of their facilities. Read the open access article here.
-
- Development and data holdings updates as of March 1st:
- Website and API
- [new] Blog: Informed Transformation: User Feedback’s Role in the ADS to SciX Transition
- [new] Biblib: added a parameter to indicate user permissions (access level) of libraries
- [new] Bumblebee: added ‘Publisher’ field to abstract pages, with implementations on quick links and full text source links
- [improved] Bumblebee: Default collections to search are now astronomy & physics; updated settings to customize default collection(s) to be searched, or search ‘all’ collections as the default
- [improved] Help pages: updated Solr fields & operators documentation
- [improved] Export: implemented support for new doctype of ‘dataset’, and updated BibTeX pubtype
- [fixed] Bumblebee: fixed missing metrics bug
- [fixed] ORCID: fixed bug where verified claims sometimes weren’t updating status from “pending” in local profile storage
- [ops] Tugboat: maintenance to allow rebuilding of deployable image
- [ops] Bumblebee maintenance updates to GA4, app settings styling, and API
- Data holdings and pipelines
- 285.8k new records, 3.9M new citations
- Website and API
Development details
February 2024
- Announcements:
- Did you miss the ADS presentations during last month’s AAS meeting? We linked our presentations to the “Join ADS/Science Explorer (SciX) at the American Astronomical Society (AAS) Conference” blog post so you can review them at your leisure. Check out the presentation highilghts below:
- We also invite you to view the ADS & SciX posters from the American Geophysical Union Fall Meeting using the links below, viewable through March 2024.
- Development and data holdings updates as of February 1st:
- Website and API
- [new] Export: Option to export a mapping of bibstem to publisher
- [fixed] Biblib: fixed library count error
- [fixed] ORCID: fixed logging messages
- [fixed] Resolver Gateway: fixed for links from myads with params
- [ops] General SciX layout updates
- [ops] Updated ORCID instructions on SciX help pages
- Data holdings and pipelines
- 243.5k new records, 1.63M new citations
- Website and API
Development details
January 2024
- Announcements:
- The ADS/SciX team will be attending the 243rd Meeting of the American Astronomical Society from 7-11 January 2024 in New Orleans, LA. We invite you to view a detailed schedule of planned ADS/SciX conference presentations here and encourage you to connect with us for a demonstration of the new Science Explorer (SciX) which was successfully beta launched on 11 December 2023 at SciXplorer.org. Staff will also be available at the Center for Astrophysics booth #315 & NASA booth #702 throughout the conference to answer questions about the ADS to SciX transition.
- Applications are now being accepted through 31 January 2024 for a new Earth Science Project Scientist position who will work to establish and maintain the Science Explorer (SciX) as a world leading information resource for Earth Science. Duties of this job include serving as the principal SciX scientific resource for Earth Science, developing new methods to search, discover, and use research data and publications, and serving as a research scientist at the intersection of Earth and Information Science. The employee will devote 30% of their time to original research in Earth Science. To learn more or apply, please visit the USAJOBS recruitment here.
- The Science Explorer was featured as an open science success story in the NASA Transform to Open Science (TOPS) blog last month. We invite you to read the story highlighting the SciX launch here.
- Development and data holdings updates as of January 1st:
- Website and API
- [new] Notes feature: Users can add notes to documents in their libraries
- [new] Timestamp sort: Users can sort documents within a library by date the document was added to the library
- [improved] Updated help pages to include
xe(e-print comments) in the list of fields available for custom export - [fixed] Biblib: Users were erroneously able to copy their own library into a library they did not have permissions to edit
- [fixed] Export: author separator issue for custom format, and misc publisher issue for bibtex format
- [ops] Solr schema now supports the
hasfield which stores the names of fields that exist for a given record. - [ops] Updated and refactored SciX about/blog/help pages
- [ops] Updated careers page: Project Scientist for Earth Science position
- Data holdings and pipelines
- 339.6K new records, and 5.79M new citations
- Website and API
Development details
December 2023
- Announcements:
- The repository has reached a new peak of 20 million records! A significant increase in Earth Science content has been included over the past month in expanding bibliographic content with the launch of SciX.
- We’re pleased to announce the unveiling of the Science Explorer (SciX) at the American Geophysical Union Fall Meeting (11-15 December) in San Francisco. Join us at booth #649 or the NASA Booth #531 (Demo Kiosk #2) in the Exhibit Hall for an exclusive introduction to the SciX platform. Our team’s AGU schedule is packed with engaging presentations, including: demos, AGU poster and oral presentations, and an intro to SciX at the NASA Hyperwall. For a detailed list of planned activities, visit our blog here. See you soon at AGU!
- The ADS Users Group met last month to learn about what we are working on now and our plans for the next year of growth as SciX. Curious? Visit the Users Group page to view our presentations.
- Development and data holdings updates as of December 1st:
- Website and API
- [new] About pages: Added Stephanie Jarmak, Project Scientist for Planetary Science, to the team page
- [new] Journals database: When a user makes a query to the
/issnendpoint, the return body will now include the abbreviated publisher name. - [new] The data schema now includes the
hasfield: a pre-computed field that indicates whether a subset of Solr fields are populated for a given entry. - [improved] Updated source links label
arxivtopreprintfor be more general/appropriate for other preprint sources - [fixed] Disabled acronym expansion for
_nosynfields to prevent incorrect exact queries when searching with “=” - [ops] Upgraded the Bumblebee web application to Node 16 and updated to Recaptcha v3
- [ops] Resolver service and gateway maintenance: Now accepts link sub type as is, rather than converting it to upper case
- Data holdings and pipelines
- 1.69M new records, and 9.78M new citations
- Website and API
Development details
November 2023
- Announcements:
- Please tell us what you think! We value your perspective! Is something bothering you? Is there something you would like to see? Like something? Please complete our brief survey by 14 November to help enhance the ADS user experience and guide innovation.
- We have a new blog post, SciX Models and Datasets, that discusses the machine learning models and datasets created by the ADS team to support our platform and curation.
- If you are attending the 2023 Astronomical Data Analysis Software & Systems XXXIII conference, please join us for the ADASS Prize for an Outstanding Contribution to Astronomical Software award and talk on 9 November, from 9:30-10:00 am when Alberto Accommazzi will be accepting the award on behalf of the ADS Team.
- Development and data holdings updates as of November 1st:
- Website and API
- [new] Published new blog post about SciX Models and Datasets
- [fixed] ORCID: Changed bibcode in the ORCID module to keep string type consistent
- [ops] Migration to Gradle: Changed the build system to Gradle instead of Ant, greatly reducing build times
- [ops] Updated Ruby/Jekyll install instructions for developers maintaining the ADS Help and Blog pages
- Data holdings and pipelines
- 315.5k new records, and 2.25M new citations
- Website and API
October 2023
- Development and data holdings updates as of October 1st:
- Website and API
- [fixed] Reference Service when checking the link for an unknown data type
- [ops] Oracle maintenance on the new /cleanup endpoint
- Data holdings and pipelines
- 193.3k new bibcodes, 1.74M new citations
- Website and API
September 2023
- Announcements:
- We are very excited to announce that during the summer, four new employees joined the ADS team:
- Jennifer Bartlett, ADS Project Scientist for Astrophysics
- Fernanda de Macedo Alves, Back-End Developer
- Jean-Claude Paquin, Back-End Developer (Search)
- Mugdha Polimera, in the role of Back-End Developer
- The 2023 ADASS Prize for an Outstanding Contribution to Astronomical Software was awarded to Alberto Accomazzi and the ADS team
- We are very excited to announce that during the summer, four new employees joined the ADS team:
- Development and data holdings updates as of September 1st:
- Website and API
- [new] Added our Database Update Policy to the Help pages, which describes our holdings update schedule
- [improved] Bumblebee: Updated search examples on main page
- [improved] Export: Added two new author formats for custom export
- [improved] Help pages: Updated info about custom formats for exporting authors
- [improved] Help pages: Added JATS XML to list of export formats
- [ops] About pages: Added two new Back End Development team members to the Team page - Fernanda de Macedo Alves and Jean-Claude Paquin
- [ops] Bumblebee: Added JATS XML export format
- [ops] Bumblebee: Updated publisher ordering for link generator
- Data holdings and pipelines
- 97k new bibcodes, 1.84M new citations
- Website and API
August 2023
- Development and data holdings updates as of August 1st:
- Website and API
- [improved] Export: Made adjustments to JATS XML
- [improved] Resolver: Removed constraint that requires data link sub types
- [ops] About pages: Added Daniel Chivvis, Digital Technologies Development Librarian, to the Team page
- [ops] Bumblebee: Moved src/libs into source control; added fix for resource ordering
- Data holdings and pipelines
- 83k new bibcodes, 1.22M new citations
- Website and API
Development details
July 2023
- Announcements:
- The position for Project Scientist for Earth Science at ADS is still open! The scientist will work to develop the Science Explorer platform and devote 30% of their time to do original research in Earth Science. Find out more and apply here.
- Development and data holdings updates as of July 7th:
- Website and API
- [new] ADS Libraries: Added raw output option that allows the user to return the exact list of bibcodes that are saved in the library via the API
- [new] Export: JATS export feature added and updated
- [new] Resolver: Added EMAC to data sources
- [improved] Export: Added two new specifiers, for number of references and for eprint comments, for custom formats
- [fixed] Resolver: bug fixed for when parameters are included in the query
- [ops] About pages: Updated job title for Dr. Kelly Lockhart, and moved Dr. Sergi Blanco-Cuaresma from active employees to research associates
- [ops] Oracle: doc matching bug fixed and tests added
- [ops] Bumblebee: Added Google Analytics 4 script
- Data holdings and pipelines
- 59.3k new bibcodes, 2.59M new citations
- Website and API
Development details
June 2023
- Announcements:
- ADS is hiring a Project Scientist for Earth Science, who will work to establish and maintain the ADS as a world leading information resource for Earth Science and related disciplines. The employee will devote 30% of their time to do original research in Earth science. Find out more and apply here.
- Development and data holdings updates as of June 1st:
- Website and API
- [fixed] Fixed a bug in the bibcode section of the feedback form
- [fixed] Fixed date parsing issue
- [fixed] Journals Database: API fix for 500 errors on the /holdings endpoint
- [ops] Maintenance to Reference Resolver
- [ops] About pages: Removed PS scientist job listing
- [ops] Added endpoint to enable/disable all myADS for a user
- Data holdings and pipelines
- 68k new bibcodes, 739k new citations
- Website and API
Development details
May 2023
- Announcements:
- We’ve published two new blog posts about the ADS Curation Model, and the Science Explorer (SciX) Expansion Project.
- Harry Blom joined our team as SciX’s Senior Publishing Liaison. Harry provides advice on publishing partner collaborations and supports the expansion of ADS to include the research results from disciplines funded by NASA.
- Development and data holdings updates as of May 1st:
- Website and API
- [new] 2 new blog posts about the ADS Curation Model, and the Science Explorer (SciX) Expansion Project
- [new] New Help Page describing the ADS Curation Model
- [new] Added Dr. Harry Blom, Senior Publishing Liaison, to our Team page
- [improved] Libraries: Adds paging to /libraries/ GET request to improve performance when a user has a large number of libraries.
- [ops] Dependency updates
- Data holdings and pipelines
- 180k new bibcodes, 1.59M new citations
- Website and API
Development details
April 2023
- Announcements:
- The 2022 ADSUG report is now available.
- Development and data holdings updates as of April 1st:
- Website and API
- [new] About pages: Added link to 2022 ADSUG report
- [new] Help pages: Added page with #ADSHelp tweets, which contain quick tips and screenshots or short GIFs
- [new] Libraries: Added new endpoint /biblib/query that allows items to be added to a library by supplying /search query parameters
- [new] Journals: Adds the ability to search the journals database on a user-supplied ISSN to return the ADS bibstem and Journal name if available.
- [improved] Libraries: Added versioning to libraries for ease of restoration in the event a user wishes to revert library versions; updated adding documents to library function to validate existence of bibcodes
- [ops] Libraries: efficiency improvements to fetching list of libraries
- Data holdings and pipelines
- 460k new bibcodes, 3.7M new citations
- ADS has begun the process of ingesting our new Earth Science holdings. More information and instructions on accessing these holdings will be available soon.
- Website and API
March 2023
- Announcements:
- ADS is hiring a Project Scientist for Planetary Science, who will work to establish and maintain the ADS as a world leading information resource for planetary science and related disciplines. The employee will devote 30% of their time to do original research in planetary science. Find out more and apply here.
- Development and data holdings updates as of March 1st:
- Website and API
- [new] About page: Planetary science project scientist job ad posted
- [fixed] Website: feedback form fixes
- [fixed] Recommender: fixes in support of doc matching pipeline
- [fixed] Blog: fixed formatting of main blog post listing so thumbnail image doesn’t overlap with blog titles when at a medium screen width
- Data holdings and pipelines
- 47.3k new bibcodes, 757.6k new citations
- Website and API
Development details
February 2023
- Announcements:
- The ADS team participated to the 241st meeting of the American Astronomical Society in Seattle with three presentations:
- ADS is still hiring! We’ll soon have a position open for a Project Scientist for Planetary Science. We’re also looking for candidates for three technical positions: a back-office developer experienced with Python, a search + back-office developer knowledgeable in Java and Python, and a DevOps engineer to manage our software infrastructure. For more details and to apply, visit our Careers page.
- Development and data holdings updates as of February 1st:
- Website and API
- [improved] Recommender: Enable matching on DOI, if DOI is present in pubnote
- [fixed] Export: fixed bug with custom export when author has no first name, better handle multiple DOIs
- [ops] Journals: refactored code
- Data holdings and pipelines
- 61.4k new bibcodes, 1.13M new citations
- Website and API
Development details
January 2023
- Announcements:
- ADS will be participating at the 241st AAS meeting in Seattle with a booth (#326), three iPoster presentations (on document matching, software citation, and machine learning activities), exhibitor presentations (Tuesday, January 10th at 9:30am & Wednesday January 11th at 10:30am in the exhibit hall), and a Hyperwall talk at the NASA booth (Monday, January 9th at 9:35am). Please stop by to say hi!
- We published a new blog post about our plans to integrate the Unified Astronomy Thesaurus in ADS Search and Discovery.
- ADS is still hiring! We’re looking for candidates for four positions: an astrophysics project scientist (30% research time), a back-office developer experienced with Python (new!), a search + back-office developer knowledgeable in Java and Python, and a DevOps engineer to manage our software infrastructure. For more details and to apply, visit our Careers page.
- The ADS database has reached 17 million records and nearly 160 million citations!
- Development and data holdings updates as of January 1st:
- Website and API
- [new] Blog: new blog post on the Unified Astronomy Thesaurus and its integration into ADS
- [improved] Website: Fixed styling of search bar so text and the clear button do not overlap, updated author search examples, removed message referring to ADS Classic credentials
- [ops] Search engine: fixed bad SSL certificate, updated schema
- [ops] Blog: edited templates to better format multiple authors and their affiliations
- Data holdings and pipelines
- 62.3k new bibcodes, 1.2M new citations
- Website and API
Development details
- Bumblebee (front-end/website) releases
- Solr (search engine) releases
December 2022
- Announcements:
- We held our annual ADS Users Group meeting virtually November 9th and 10th, where we updated our advisory committee on our progress this year and our plans for the future. The presentations from the meeting are now available and the committee’s report will be available soon.
- We are still accepting applications for the position of Project Scientist for Astrophysics, and have openings for two developers. Find out more and apply here.
- We hosted (virtually) the first Workshop on Information Extraction from the Scientific literature (WIESP). The full agenda, with links to the talks, can be viewed here.
- Development and data holdings updates as of December 1st:
- Website and API
- [new] About pages: presentations from our November 2022 ADSUG meeting are now available, with the committee’s report to follow soon
- [fixed] Author affiliation report: changed default if no month is provided from “00” to “01”; fixed logic to more reliably use the canonical affiliations, if available
- [fixed] Oracle (docmatching): fixed a bug in matching by DOI, and to allow more than one pubnote
- [ops] Help and about pages: updated team members’ titles, fixed broken links
- Data holdings and pipelines
- 208k new bibcodes, 2.05M new citations
- Website and API
Development details
November 2022
- Announcements:
- ADS has an opening for the Project Scientist for Astrophysics, who will work to establish and maintain the ADS as a world leading information resource for astrophysics and related disciplines. The employee will devote 30% of their time to do original research in astrophysics. The project also has two developer positions still open. Find out more and apply here.
- The ADS team will be hosting the 2022 ADS Users Group meeting November 9 and 10. Do you have a request, suggestion, or general feedback about the ADS project? You’re welcome to submit it to the advisory panel by emailing us at adshelp@cfa.harvard.edu with “ADSUG” in the subject line.
- ADS maintains a database of summary information about the publications we index—the Journals database (JournalsDB). It includes information that the ADS uses for internal content management, but that is also useful for librarians and other content managers to know about how specific titles are classified and what the ADS’ holdings are for individual titles and volumes. More information is available on our API documentation and in our example Jupyter notebook.
- ADS pipelines have been updated to calculate metrics for software records ingested from Zenodo. Metrics for these records can be examined individually or in aggregate with any other records.
- Development and data holdings updates as of November 1st:
- Website and API
- [new] Journals service: initial release
- [improved] Website: updated language on settings page and facets, adjusted sort order of autocomplete options
- [fixed] Website: fixed bug with banner styling
- [fixed] Metrics: fixed bug in citation histogram when max year is in the future
- [fixed] Recommender: fixed scoring bugs
- [ops] Help page: updated privacy policy
- [ops] Recommender: updates to prep for arXiv DOIs
- Data holdings and pipelines
- 102k new bibcodes, 2.6M new citations
- Website and API
Development details
October 2022
- Announcements:
- The ADS curation team rolled out a new harvest and curation process for retrieving astronomy & astrophysics books from HOLLIS (Harvard Online Library); over 800 books were added this month.
- Development and data holdings updates as of October 1st:
- Website and API
- [new] Two new blog posts: “The ADS Object Search: How to Find Astronomical Objects in the Literature”, “ADS Docmatcher”
- [new] Reference service: added /parse endpoint
- [improved] Recommender: added erratum and bookreview special cases
- [fixed] Search engine: fixed Russian transliteration issue
- [fixed] Reference service: fixed author parsing
- [ops] Recommender: Retrained model
- Data holdings and pipelines
- 53.8k new bibcodes, 383k new citations
- Ingested 1600 new and/or updated monographs from Princeton University Press and Harvard Libraries and 1500 LPI Bulletin entries, which required a lot of manual curation and filled in gaps in our planetary science holdings
- Website and API
Development details
September 2022
- Announcements:
- The ADS team has been recently selected by NASA to extend its coverage and services into the fields of planetary science, heliophysics, earth sciences, and NASA funded research in the biological and physical sciences. This will create new opportunities for engagement between the ADS team and the other NASA Science Divisions, bringing together astronomers, planetary scientists, and earth scientists.
- Development and data holdings updates as of September 1st:
- Website and API
- [fixed] Export: allow LaTeX fielded encoding for bibcodes; removed escaping underscore in DOI for BibTeX
- [ops] Reduced number of retries when a query fails to avoid slowing server response
- [ops] Recommender: algorithm and efficiency improvements
- [ops] About page: updated team page, updated salary/benefits language on careers page
- Data holdings and pipelines
- 76.8k new bibcodes, 1.48M new citations
- Website and API
Development details
August 2022
- Announcements:
- ADS is still hiring! We’re looking candidates for two positions: a search + back-office developer knowledgeable in Java and Python, and a DevOps engineer to manage our software infrastructure, including search engines, relational databases, and cloud-based microservices. For more details and links to the applications, visit our Careers page.
- Development and data holdings updates as of August 1st:
- Website and API
- [new] Website: multiple DOIs on abstract pages now supported where available
- [improved] Website: updated some tooltip language
- Data holdings and pipelines
- 71.6k new bibcodes, 1.3M new citations
- Website and API
Development details
- Bumblebee (front-end/website) releases
July 2022
- Announcements:
- ADS is hiring! We’re looking for a DevOps engineer to manage our software infrastructure, including search engines, relational databases, and cloud-based microservices. We’ll also soon have an additional opening for a search+back-office developer. For more details and links to the applications, visit our Careers page.
- ADS is co-organizing WIESP 2022, a Natural Language Processing (NLP) workshop, for AACL-IJCNLP 2022. If you’re interested in participating, check out our challenge/shared task (register here; final submission deadline: August 10th).
- Development and data holdings updates as of July 1st:
- Website and API
- [improved] Export: Added ASCII field encoding as an option for custom export formats, updated help pages with instructions for this encoding
- [improved] Metrics: Added support for indices for individual papers
- [fixed] Website: fixed bug that caused parent nodes to be displayed in facets
- [ops] Help pages: Added links to iPosters in last month’s announcements, fixed broken help page links
- [ops] About pages: Updated team bios, updated ADSUG membership and pages
- [ops] Reference service: optimizations
- Data holdings and pipelines
- 69.4k new bibcodes, 1.05M new citations
- Website and API
Development details
June 2022
- Announcements:
- ADS will be at the upcoming 240th meeting of AAS in Pasadena, CA. Visit us at our booth in the exhibit hall (in person or virtually)! We’ll have several presentations and iPosters at the meeting as well:
- NASA hyperwall talk: “How to find Experts Using the ADS,” Monday, June 13 @ 9:46 am
- “What’s New @ ADS” presentation at the exhibitors’ showcase, Monday, June 13 at 1:00 pm
- iPoster: “Automatically Detecting Facilities in the Scientific Literature Using Deep Learning Techniques”, Tuesday, June 14 @ 5:30 pm
- iPoster: “Introducing the New ADS OpenAPI Exploration Tool: Making API Access More User-Friendly”, Wednesday, June 15 @ 9:00 am
- ADS will be at the upcoming 240th meeting of AAS in Pasadena, CA. Visit us at our booth in the exhibit hall (in person or virtually)! We’ll have several presentations and iPosters at the meeting as well:
- Development and data holdings updates as of June 1st:
- Website and API
- [fixed] Fixes to metrics reads and average reads
- [ops] About pages: updated team bios
- [ops] Help pages: removed link to outdated conference proceedings submission form
- Data holdings and pipelines
- 48k new bibcodes, 865k new citations
- Website and API
May 2022
- Development and data holdings updates as of May 1st:
- Website and API
- [ops] Updated Solr search engine configuration
- Data holdings and pipelines
- 70.7k new bibcodes, 1.36M new citations
- Website and API
Development details
- Solr (search engine) releases
April 2022
- Announcements:
- We completed the first month of our #ADShelp Twitter campaign, earning 320 engagements (likes, retweets, and replies) overall. Our most popular tweets included one about customizing your BibTeX citation keys and one about generating the co-author report for NSF grant applications. Let us know any topics you’d like to see us cover in future campaigns.
- Development and data holdings updates as of April 1st:
- Website and API
- [new] Libraries: Show number of records visible in library, with warning if different from number of records shown in library header
- [improved] Export: adjusted which fields are used for some exports when there is more than one similar field available (pub_raw instead pub, aff_canonical instead of aff)
- [improved] Search engine: reworked transliteration rules
- [ops] About page: cleaned up Team page
- Data holdings and pipelines
- 51.3k new bibcodes; 1.02M new citations
- Website and API
Development details
March 2022
- Announcements:
- We’ve migrated the serving of PDF full-text documents to ADS’s cloud platform in order to provide greater reliability and accessibility to our article archive.
- The AAS published a press release providing an update of the Asclepias project, in which ADS, Zenodo, and the AAS have collaborated to promote the preservation and citation of scientific software in the literature.
- The ADS team published a paper on its experience with accessibility of its user interface.
- We’ve started a Twitter campaign (#ADShelp) to provide better user support upon a recommendation from our users group.
- Development and data holdings updates as of March 1st:
- Website and API
- [new] Help documentation: advanced documentation on search syntax and author searching now available
- [improved] Website: improved print layout; made the bibcode a copy button on the abstract page; added “inst” to the “all search terms” list; added book author field to abstract pages; added more authors to the search examples to improve sub-field diversity
- [improved] Search engine: major update to author transliteration rules, standardizing the “ASCII-fication”
- [fixed] Website: fixed bug with public libraries getting onto users’ My Libraries lists; fixed bug causing metrics graphs to not properly update when switching views; fixed author list semicolon issue; fixes to feedback forms
- [fixed] Search engine: removed obsolete fields and made some facet indices case insensitive
- [ops] Website: small fixes to favicon and build errors; improved resource timeouts
- [ops] Search engine: testing custom implementations of topn()
- Data holdings and pipelines
- 54.3k new bibcodes; 992k new citations
- Website and API
Development details
February 2022
- Announcements:
- A recent presentation about ADS by PI Alberto Accomazzi is available online.
- Development and data holdings updates as of February 1st:
- Website and API
- [improved] Help pages: Moved information on Author Affiliations report, used to assist with compiling a list of co-authors for NSF and other grant applications, from FAQ to its own help page
- [improved] Export: Allow %X, the arXiv ID, in the custom citation key in BibTeX exports
- [fixed] Export: added editor to Endnote and Refworks export formats; display page range, if available, for Endnote and Medlars export formats; fixed how book titles are exported in Endnote format; fixed bug with custom format page range %p-%P when end page isn’t available; for BibTex format, replaced @INBOOK with @INCOLLECTION
- [ops] We had two brief outages, one due to a CDN outage and one due to a Kubernetes master node issue.
- Data holdings and pipelines
- 91.3k new bibcodes; 772k new citations
- Website and API
Development details
- Export service releases
January 2022
- Announcements:
- The report from the ADS Users Group meeting in November 2021 is now available.
- The ADS participated at the 2021 Fall AGU meeting with a poster presentation (also available as an ESSOAr preprint) about the expansion of FAIR content in its database.
- Development and data holdings updates as of January 1st:
- Website and API
- [new] About page: added link to 2021 ADSUG report
- [new] Help pages: added a help page for library set operations
- [improved] Help pages: added information about library collaborators
- [fixed] Search engine: Fixed scoring for second-order operators, fixed multiphrase token search expansion, fixed issue with citation retrieval failing randomly
- [ops] Search engine: Updated schema to not copy/duplicate identifiers, security fixes
- Data holdings and pipelines
- 46k new bibcodes; 700k new citations
- Website and API
Development details
- ADS Web Services releases
- Solr (search engine) releases
December 2021
- Announcements:
- We held our annual ADS Users Group meeting virtually November 15th and 16th, where we updated our advisory committee on our progress this year and our plans for the future. The presentations from the meeting are now available and the committee’s report will be available soon.
- We’ve begun expanding our holdings in planetary science and heliophysics. For a behind-the-scenes look at what that means for our curation team, read our new blog post on using our API to complete a curation project in conjunction with the Space Sciences and Astrobiology Division at NASA Ames Research Center (ARC/SSAD).
- Thanks to help from the AAS, we have incorporated more than 20,000 PhD theses from the AstroGen project, including many non-US theses. Although these do not have abstracts, many of them do have links to their fulltext sources. If you find your thesis is still missing, or that it is duplicated, or if you would like to add an abstract, please submit a correction through our feedback form.
- The ADS database has reached 16 million records and over 143 million citations!
- Development and data holdings updates as of December 1st:
- Website and API
- [new] Blog: new blog post on using our API internally to help with curation
- [new] Help pages: added conference handouts to our help pages
- [new] About page: presentations from our November 2021 ADSUG meeting are now available, with the committee’s report to follow soon; added three new employees, Tom Allen, Taylor Jacovich, and Tom Fehring, to our Team page
- [ops] Fixed potential security issue with fetching the password reset URL
- [ops] Deployed several services (citation helper, metrics, object) under Python 3
- [ops] Help pages: cleaned up some old Classic links
- Data holdings and pipelines
- 78.6k new bibcodes; 834k new citations
- Website and API
Development details
November 2021
- Announcements:
- We’ve given our homepage search examples a refresh: the selection of search examples has been updated based on user feedback, and the author names in the examples now reflect recent prize winners.
- The ADS team will be hosting the 2021 ADS Users Group meeting November 15-16. Do you have a request, suggestion, or general feedback about the ADS project? You are welcome to submit it to the advisory panel by emailing us at adshelp@cfa.harvard.edu with “ADSUG” in the subject line.
- Development and data holdings updates as of November 1st:
- Website and API
- [improved] Website: refreshed search examples and author examples on the Modern Form homepage; improved accessibility; added more data link types
- [fixed] User accounts: fixed bug that caused email addresses associated with user accounts to be case sensitive
- [fixed] Website: fixed several feedback form bugs
- [ops] Help pages: updated language about API terms of use
- Data holdings and pipelines
- 54.8k new bibcodes; 1.34M new citations
- Website and API
Development details
October 2021
- Announcements:
- The 2021 ADS Users Group (ADSUG) Meeting will take place virtually on November 15-16. ADS users are welcome to submit feedback or questions to the panel by sending an email to adshelp@cfa.harvard.edu with “ADSUG” in the subject line. The meeting program and presentations will be posted on the ADSUG website.
- Development and data holdings updates as of October 1st:
- Website and API
- [improved] Website: added dark mode to dropdown menus, added more information to 404 pages as applicable, added Dataverse data link type
- [improved] Resolver: added more data link types
- [improved] About page: updated the ADS Users Group page with the new members
- [fixed] Website: Fixed bug with dropdown menus, fixed add-to-library bug when there are no existing libraries, fixed bug with feedback forms
- [fixed] Classic translator: Fixed bug to recognize multi-part last names with no first initial given
- [ops] Made the Solr service compatible with Python 3
- Data holdings and pipelines
- 172.9k new bibcodes; 1.56M new citations
- Added data links to 5600 AGU articles
- Added 480 software packages cited by 500+ AGU articles
- Website and API
Development details
September 2021
- Announcements:
- On August 16th, ADS welcomed Jenny Koch as our newest team member, in the position of digital technologies development librarian. Jenny has a Master of Library & Information Science from Simmons College and comes to us from the NASA Scientific and Technical Information (STI) Program at NASA Langley. Welcome to the team, Jenny!
- Development and data holdings updates as of September 1st:
- Website and API
- [new] Export: Added new custom author format %k to allow all authors to be formatted as “Firstname M. Lastname”
- [new] Help pages and blog: New blog post on OpenAPI help documentation; updated help documentation to include information on new custom export author format %k
- [improved] Website: improved speed and clarity of the graphs in the right pane of the search results page; updated ORCID mode switch to use “ORCID green”
- [fixed] Website: fixed bug with year graph on search results page; fixed description on “property” in all search terms menu
- [fixed] Export: improved escaping in custom export formats
- [fixed] Resolver: fixed bug with wrong in-house URL for associated links
- Data holdings and pipelines
- 44.4k new bibcodes; 1.09M new citations
- Website and API
Development details
August 2021
- Announcements:
- You can now easily download CSV data behind the histograms displayed with search results (“Years,” “Citations,” “Reads”) as well as visualizations (Citations Metrics, Author and Paper Networks, Concept Cloud and Results Graph)—click the download button on the histogram or visualization to download the CSV file.
- Interested in trying our new API docs but unsure where to begin? Read our blog post for an overview and some usage examples to get you started.
- Development and data holdings updates as of August 1st:
- Website and API
- [new] Website: Added button on metrics and histograms to download data as a CSV
- [improved] Website: Added descriptions to “All Search Terms” dropdown menu; updated API help page link on homepage
- [fixed] Website: Fixed bugs on feedback form, with highlights, and on abstract page for papers with no authors; updated ORCID icons to use correct shade of green; updated a journal bibstem on Paper Form search
- [fixed] Export: Fixed links for showing number of citations and references; added total number of citations to XML exports
- [ops] Website: updated resource timeout to keep site from hanging while loading
- [ops] Help docs: added OpenAPI documentation for internal endpoints
- Data holdings and pipelines
- 103.9k new bibcodes; 1.28M new citations
- Website and API
Development details
July 2021
- Announcements:
- ADS is pleased to announce our new name change policy. We recognize that users change their names for many reasons, and some users desire or require more privacy around their previous names. We will now update the searchable metadata and pages within ADS to reflect an author’s current name, as need requires, even if that differs from the publisher’s metadata for those papers.
- Our user-facing API is now fully documented using the OpenAPI specification! Explore the API and make test API calls, all from the convenience of your browser.
- Now available: dark mode! You can toggle the setting manually or let your system’s setting turn it on for you.
- Development and data holdings updates as of July 1st:
- Website and API
- [new] Website: Added dark mode option; added ORCID ID search links for authors on the abstract page
- [new] Help pages: New ADS name change policy, new OpenAPI full API documentation
- [improved] Website: HTML in abstracts is now rendered correctly; external links for associated works are now supported; totals are now shown on metrics histograms when mousing over
- [improved] Export: added 5 new journal macros to AASTeX exports
- [improved] Help pages: restructured main API help page; added journal macros and macros .sty pages (moved from Classic)
- [fixed] Website: results page sidebar no longer disappears upon login; fixes for library page bugs; fixed bug in citations/references tabs on abstract screen when paper has no title
- Data holdings and pipelines
- 104.7k new bibcodes; 903.2k new citations
- Website and API
Development details
June 2021
- Announcements:
- Join our team! We have a new job posting for a back-office developer and/or data scientist, as well as two existing postings: one for a part-time astronomer to prep machine learning datasets and perform data analysis and one for a digital technologies and development librarian.
- New content in ADS! We are improving our coverage of Planetary Science and Heliophysics to support research in those disciplines and facilitate interdisciplinary studies in Space Sciences. Look for a steady increase in the number of journals and conferences relevant to these two disciplines in the coming year.
- Coming soon! A much requested UI feature: dark mode.
- Development and data holdings updates as of June 1st:
- Website and API
- [improved] Website: reorganized settings page into search and export settings; improved functionality of Add to Library widget; improved hover-over functionality to make usable on touch screens; minor improvements for library display, mobile login and registration pages, mobile menus, mobile layouts
- [improved] Export: added two new author formats, O and o
- [fixed] Website fixes: applied institution facets no longer show as “affiliations,” fixed several small bugs with the fulltext sources dropdown icon on the search results page, fixed small styling bug for Explore menu options, removed My Homepage, fixed 404 error for older browsers
- [fixed] Link resolver: fixed some small bugs after Python 3 upgrade
- [ops] Graphics: simplified database schema
- Data holdings and pipelines
- 127k new bibcodes; 1.08M new citations
- Website and API
Development details
May 2021
- Announcements:
- We’re hiring! We have one position available for a part-time astronomer to prep machine learning datasets and perform data analysis and one for a digital technologies and development librarian. We’ll also soon have an additional opening for a back-office developer. For more details and links to the applications, visit our Careers page.
- Development and data holdings updates as of May 1st:
- Website and API
- [improved] Website: styling improvements for mobile view, libraries, link gateway, and help pages/blog
- [improved] Search: improved affiliations searching, including adding aff_id to the virtual inst search field
- [fixed] Website: removed disallowed library functionality for users with permissions other than owner/admin
- [fixed] Export: fixes for encoding when not using macros
- [ops] Made several services (author affiliation, export, harbour, resolver gateway, resolver service, vault) compatible with Python 3
- Data holdings and pipelines
- 60.8k new bibcodes; 1.49M new citations
- Website and API
Development details
- Author affiliation service releases
- Bumblebee (front-end/website) releases
- Export service releases
- Harbour service releases
- Resolver gateway releases
- Resolver service releases
- Solr (search engine) releases
- Vault releases
April 2021
- Development and data holdings updates as of April 1st:
- Website and API
- [improved] Website: several usability improvements to the mobile version of the website
- [fixed] ORCID: fix for error when claiming records with multiple bibcodes (e.g. MNRAS tmp vs. MNRAS final published version)
- [ops] About page: added new staff members Jennifer Chen and Felix Grezes to Team page
- [ops] Made several services (biblib, oracle, ORCID, tugboat) compatible with Python 3
- [ops] Website: updated NASA Cooperative Agreement info in footer
- Data holdings and pipelines
- 46.9k new bibcodes; 593.8k new citations
- New physics papers are now added weekly, instead of about every month
- Website and API
Development details
March 2021
- Announcements:
- On March 1st, the ADS project welcomed Shinyi (Jennifer) Chen and Felix Grezes as new team members. Jennifer has a Masters degree in Computer Science from USC with a Diploma in User Experience Design, bringing to the team expertise in UI/UX. Felix is a PhD Candidate in Computer Science at the CUNY Graduate Center in New York City and brings to the team an expertise in Machine Learning and Natural Language Processing. We are excited to have them both onboard!
- With the start of a new Cooperative Agreement on March 1st, NASA requested an expansion of ADS content to provide better coverage of Heliophysics and Planetary Science. We look forward to better serving both communities in the coming months and years.
- Development and data holdings updates as of March 1st:
- Website and API
- [improved] Website: Added warning if website accessed via a proxy URL, improved highlights functionality, feedback form UI improvements
- [fixed] Search engine: fixed ASCII folding issue
- [ops] Website: Feedback form fixes, dependencies clean-up, animation functionality improvements
- [ops] Made several services (citations, graphics, metrics, object) compatible with Python 3
- [ops] Search engine: upgraded to Solr v.7
- Data holdings and pipelines
- 58,000 new bibcodes, 785,000 new citations
- Website and API
Development details
- Bumblebee (front-end/website) releases
- Citation helper service releases
- Graphics service releases
- Metrics service releases
- Object service releases
- Resolver service releases
- Solr (search engine) releases
February 2021
- Announcements:
- The ADSUG final report from the November 2020 meeting is now available.
- Development and data holdings updates as of February 1st:
- Website and API
- [improved] Website: Search bar autocomplete improvements
- [ops] Website: optimizations, build improvements, feedback form fixes
- [ops] Search engine: fix for analysis error during indexing
- [ops] Fixed rate limit response headers and affinity after separating solr-service from adsws
- Data holdings and pipelines
- 158,000 new bibcodes, 1,710,000 new citations
- Website and API
Development details
January 2021
- Announcements:
- ADS will participate in the upcoming virtual AAS 237th meeting. Visit us at our booth! And come to our webinar, “Get your Personalized Notifications and Recommendations from ADS,” on Tuesday, January 12, at 4:30pm EST
- The ADS database has reached 15 million records and over 131 million citations!
- ADS is now an official member of the ORCID US community, via our parent institution, the Smithsonian Astrophysical Observatory, which gives us greater access to the ORCID ecosystem. With this upgrade, we hope to improve our ORCID integration over the coming year
- Development and data holdings updates as of January 1st:
- Website and API
- [new] Help pages: linked to new welcome video and new myADS help video
- [improved] Website: speed improvements, better browser support, better error handling
- [fixed] Libraries: fix for too-long library names
- [fixed] Website: fixed issue with URLs not accepting query params preceded by “?”
- [ops] Updated and improved new feedback form infrastructure
- [ops] Updated infrastructure for a number of microservices to support Python 3
- Data holdings and pipelines
- 54,400 new bibcodes, 576,000 new citations
- Website and API
Development details
- ADS Web Services releases
- Author affiliation service releases
- Libraries releases
- Bumblebee (front-end/website) releases
- Citation helper service releases
- Export releases
- Graphics service releases
- Harbour service releases
- Metrics service releases
- Object service releases
- Oracle (Recommender) releases
- ORCID releases
- Resolver gateway releases
- Resolver service releases
- Solr (search engine) service releases
- Tugboat releases
- Vault releases
- Visalization service releases
December 2020
- Announcements:
- We (virtually) held our annual ADS Users Group meeting November 19th and 20th, where we updated our advisory committee on our progress this year and plans for the future. The presentations from the meeting are now available and the committee’s report will be available soon.
- Development and data holdings updates as of December 1st:
- Website and API
- [new] The “Submit Updates” feedback forms have been updated and incorporated into the new ADS and no longer point to the old Classic forms.
- [new] About page: added agenda and presentations from the latest ADSUG meeting, added new team members to Team page
- [improved] Help pages: Updated FAQs to include info on building ADS URLs using arXiv IDs and DOIs and to add a pointer to the data & curation FAQs
- [fixed] Website fixes: fixed bug in Manage Collaborators tab in libraries, cleaned up requests sent when submitting a search, fixed bug in search examples on Modern Form, fixed /search(/) redirect and previous page bug
- [fixed] Export: removed linebreak from BibTex author list
- [fixed] Search engine: fixed non-ASCII double quotes bug, fixed the multi-token on first position error
- [ops] Recommendations and docmatch: updated endpoints to remove beta underscore, made connection pool optional, removed refereed from the query for querying for publisher to get matched to arXiv
- Data holdings and pipelines
- 57,400 new bibcodes, 883,000 new citations
- Website and API
Development details
November 2020
- Announcements:
- ADS is hiring! We’re looking for a machine learning engineer interested in deep learning and natural language processing—find the application linked on our Careers page.
- Development and data holdings updates as of November 1st:
- Website and API
- [new] Recommender: New service recommends articles of interest to the reader based on their history or that of other readers with similar interests
- [new] Website: added A/B testing infrastructure
- [new] Help pages: Added page on how we select journals for inclusion in our database, added info to our FAQs about our tools for assisting with NSF grant applications
- [fixed] Export: Added missing DOIs, removed line wrap in abstract in fielded format, fixed XML format header
- [fixed] Fix for non-ASCII characters in general queries
- [ops] Website: Fix build issue affecting cache-busting
- Data holdings and pipelines
- 40,000 new bibcodes, 747,000 new citations
- Website and API
Development details
October 2020
- Announcements:
- We have added personalized recommendations to the ADS home page. The next time you go to the homepage, look for the “Recommendations” tab to find papers that may be relevant to your recent reading history. In order to take advantage of this feature, make sure you have an ADS user account and are logged into the system so it can remember who you are.
- Development and data holdings updates as of October 1st:
- Website and API
- [improved] Website improvements: Affiliations facet renamed to Institutions, added Legacy Services in About menu, repositioned buttons on export page
- [improved] Export: Added IEEE export format, added %pc for page_count to custom format
- [improved] myADS email notifications: now use a smart date range—if email processing fails one day, the date range will cover the missed days
- [improved] Help pages and blog URLs now use our standard domain name (ui.adsabs.harvard.edu). Note that saved links that use the old domain, adsabs.github.io, will still work
- [fixed] Website fixes: fix for arXiv ID not showing on abstract page, made library permissions errors more readable, allowed for collection and property query params in Classic Form URLs, fixed logout bug
- Data holdings and pipelines
- 73,000 new bibcodes, 980,000 new citations
- Website and API
Development details
September 2020
- Announcements:
- ADS has written a white paper for the Planetary Science and Astrobiology Decadal Survey recommending we support planetary science literature, data products, and software at the same level that we currently support astrophysics. To sign on, add your name to the document by September 14, 2020.
- ADS is hiring! We’re seeking out a front-end software developer with experience in UX—find the application linked on our Careers page.
- The ADS Users Group will virtually hold their next annual meeting November 19–20, 2020. Contact an ADSUG member if you have feedback for the project.
- Development and data holdings updates as of September 1st:
- Website and API
- [new] New blog post about the myADS email notifications service
- [improved] myADS notifications: updates to allow private libraries to be included in notifications
- [improved] Website: accessibility updates, improvements to handling of landing page example links
- [improved] Help pages: similar() operator added to second-order operators help page
- [fixed] Website: fix to make sure search bar clears, fix bug when parsing url strings with non-encoded ‘%’
- [fixed] Propagate HTTP search errors instead of failing with 500 status code
- [ops] Fixed Slack comment encoding
- [ops] Updated adsmutils version, rate limits in solr-service
- [ops] Remove reliance on QID for general myADS queries
- [ops] Better verification of access tokens in the vault service
- [ops] Disallow inactive accounts from signing in
- Data holdings and pipelines
- 61,041 more bibcodes, 753,916 more citations
- Website and API
Development details
August 2020
- Development and data holdings updates as of August 1st:
- Website and API
- [New] Framework for creating A/B experiments added to UI
- [Fixed] Several minor maintenance releases to a couple of microservices
- Data holdings and pipelines
- 64,465 more bibcodes, 753,524 more citations
- Website and API
Development details
July 2020
- Development and data holdings updates as of July 1st:
- Website and API
- [Fixed] Several fixes to UI, among which
- Several fixes for myADS
- Missing capturing full ORCID ids when last character ‘X’
- Make library collaborators component fetch users
- Update error handling and fix initial dispatch for adding library collaborators
- [improvement] All microservices have been updates to work with a new rate limits configuration
- [Fixed] Several fixes to UI, among which
- Data holdings and pipelines
- 80,483 more bibcodes, 896,335 more citations
- Website and API
Development details
- ADS Web Services releases
- Author-affiliation
- Biblib
- v1.0.34-hamma
- v1.0.34-gamma
- v1.0.34-delta
- v1.0.34-beta
- v1.0.34-alpha
- v1.0.33
- v1.0.32
- v1.0.31
- v1.0.30
- Bumblebee (front-end/website) releases
- Citation-Helper
- Export
- Graphics
- Harbour
- Metrics
- Object
- ORCID
- Resolver-Gateway
- Resolver-Service
- Tugboat
- Vault
- Vis
June 2020
- Development and data holdings updates as of June 1st:
- Website and API
- [new] Add myADS dashboard
- [new] Blog post on updates to the UI
- [improvement] Customize Settings is now called Settings
- [Fixed] Fix to bug in delete button for Custom Format (in Settings)
- Data holdings and pipelines
- 145,262 more bibcodes, 624,039 more citations
- Website and API
Development details
May 2020
- Development and data holdings updates as of May 1st:
- Website and API
- [improved] Add help menu showing hotkeys
- [improved] Add new journal format preference
- [fixed] Libraries now return library owner correctly
- Data holdings and pipelines
- 70,057 more bibcodes, 2,846,429 more citations
- Website and API
Development details
April 2020
- Development and data holdings updates as of April 1st:
- Website and API
- [improved] Libraries: improved readability of emails notifying users of updated permissions
- [ops] Released myADS backend for beta testing
- [ops] Made author_count a stored field to support optimized UI requests
- Data holdings and pipelines
- 76,515 more bibcodes, 1,399,160 more citations
- [ops] New GCN Circulars are now being added on a weekly basis, and missing abstracts and metadata for older abstracts are slowly being filled in
- Website and API
Development details
March 2020
- Development and data holdings updates as of March 1st:
- Website and API
- [new] Can now add library collaborators with varying permission levels, under Manage Collaborators on the library’s page
- [new] Can now exclude selected records from a results list
- [new] Simple hotkeys are now available for the search results page, such as using the left and right arrows to page through results (full documentation forthcoming)
- [improved] Website improvements: improved linking to help pages and accessibility documents, added simple search on libraries page, improved styling for printing the results page, no longer wrapping the current query with extraneous parentheses when running a second-order query from the Explore menu
- [improved] Export improvements: added doctype of editorial, which maps to @article in BibTeX; now support BibTeX export without AASTeX macros; improved tech report output; added enumeration to BibTeX cite keys if duplicates exist in the export
- [improved] Search: improved query parsing
- [fixed] Fix issues on abstract page related to showing the abstract and expanding author lists
- [fixed] Export fixes: removed quotes around month and year in BibTeX exports, no longer encoding linefeeds for html encoding, now exporting DOI if no volume and page exist for a record
- [fixed] Search: implemented a fix for long phrase searches that timeout or return no results
- [fixed] Fix for entry dates in myADS email query links
- [ops] Website: improved Google Analytics implementation by removing duplicate calls
- [ops] Search: implemented better handling and protections for long-running searches
- Data holdings and pipelines
- 54,037 more bibcodes and 697,752 more citations
- Website and API
Development details
- ADS Web Services releases
- Author affiliation releases
- Bumblebee (front-end/website) releases
- Export service releases
- Graphics releases
- Metrics releases
- ORCID releases
- Solr (search engine) releases
- Solr (search engine) service releases
- Tugboat releases
February 2020
- Development and data holdings updates as of February 1st:
- Website and API
- [new] Search: Added affil as virtual field for affiliations, including aff, aff_id, inst fields
- [new] New blog post on searching by author affiliations
- [new] The ADS Users Group final report for the November 2019 meeting is now available on the ADSUG page
- [new] Added Accessibility page to the help pages
- [improved] Users will be emailed when their library permissions are changed
- [improved] Website improvements: updated fields listing in “All Search Terms” dropdown menu and autocomplete, including changing “database” to “collection” in autocomplete to better match facets; added Clear buttons to Paper Form
- [improved] Export: for BibTeX book exports, use pub instead of pub_raw and aff instead of aff_raw
- [improved] Help pages: added search syntax for author_count field, removed outdated Classic references, renamed “Tutorials” section to “Troubleshooting” and cleaned up contents, added link to YouTube channel in “Videos” section
- [fixed] Fixed bug for too-long library descriptions
- [fixed] Export: fixed AASTeX format with comma in citation before ampersand (&)
- Data holdings and pipelines
- 27,235 more bibcodes, 363,886 more citations
- [fixed] Bug fixes to resolve a number of errors in the fulltext extraction pipeline, including removing non-standard parsing, ignoring poorly formatted facilities information, expanding the encoding and decoding used by the XML parser to use in the HTML parser, and improving CDATA removal to handle invalid XML content
- Website and API
Development details
January 2020
- Development and data holdings updates as of January 1st:
- Website and API
- [improved] Website improvements: accessibility updates to bring site to WCAG 2.0 AA & AAA baselines; if query entered in all caps returns no results, suggest a lowercase version of the query
- [improved] Added API support for export of individual citation/usage histograms (equivalent to the Classic nph-ref_history?refs=CITATIONSi|AR)
- [improved] Updated search syntax: collection: can now be searched as for database:, as in collection:astronomy
- [fixed] Website fixes: fixed potential security issue; increased number of papers that can be processed at once in metrics
- [fixed] Fixed bug in author wildcard search
- [fixed] Bugfix for generating transliterations
- [fixed] Classic query translator: fixed issue with db_key2 translation in myADS queries; bugfixes for arXiv queries in myADS; fix to verify that dates are valid numbers; bugfix if a start param is provided but an ending param is not
- [ops] In the citation helper, use the token of the user instead of the service-level token
- Data holdings and pipelines
- 85,622 more records, 974,312 more citations
- 162 notebooks from the PHaEDRA project were added (representing 34,797 scans)
- [new] The fulltext pipeline is now extracting facilities information where available
- [ops] A Unicode bug was fixed in the fulltext pipeline, reducing overall extraction error rate by a factor of 20
- [ops] A test version of the new myADS pipeline was deployed for debugging and testing for future release
- Website and API
Development details
December 2019
- Development and data holdings updates as of December 1st:
- Website and API
- [improved] Updates to the Paper Form: added ApJL to Publication field autocomplete; added a link to a full list of available bibstems
- [improved] Improved access for reference managers
- [improved] Added unicode support for author affiliation report
- [improved] Added several new data link types
- [fixed] Fixes to the Paper Form: removed the requirement to provide a Publication in the Journal Search, updated styling
- [fixed] Fixes to the author affiliation report, including selecting the first non-(None) entries in author affiliations
- [fixed] Fixes in the export service, including adding an attribute to the Dublin Core XML (DC-XML)
- [fixed] Fixes and improvements to myADS query translations
- [ops] Improved internal logging
- Data holdings and pipelines
- 45,328 more records, 506,719 more citations
- [ops] A Solr schema change required reprocessing all bibliographic data
- [ops] The affiliations database was updated with new affiliations strings
- [ops] Over the past week, 99.8% of queries returned successfully
- [ops] The fulltext pipeline now has error reporting
- Website and API
Development details
- ADS Web Services releases
- Author affiliation releases
- Bumblebee (front-end/website) releases
- Export releases
- Resolver service releases
- Solr (search engine) service releases
- Tugboat releases
November 2019
- Development and data holdings updates as of November 1st:
- Website and API
- [new] Basic, HTML version of ADS now available; links are shown in the splash screen and footer
- [new] “A Final Farewell to ADS Classic,” a blog post with more information about the retirement of Classic
- [new] Added information on data curation and availability, formerly available in ADS Classic, to a new Legacy menu in the help pages
- [new] Added handling for myADS queries linked in Classic-generated myADS emails
- [improved] Updates to the Paper Form, including addition of the reference resolver and styling updates
- [improved] Updates to the Classic Form, including addition of a sort selection and a General collection checkbox; collection checkboxes now respect user settings selections, have updated wording
- [improved] Library updates: deleting an item from a library no longer takes you back to the first page of the library
- [improved] Added authorcutoff option for BibTeX export, to specify the max number of authors to show
- [improved] Added search syntax for searching for affiliations to help pages
- [improved] Added Github data source
- [improved] For redirected links from Classic, all warnings about using AND vs OR have been removed; ORs are no longer converted to ANDs
- [fixed] Fixes to Classic Form keyword parsing
- [fixed] Fixed normalized citation count on results page
- [fixed] Fixed bug that caused some Library Link URLs to not work properly
- [fixed] Export service: fixed ADS fielded format to return ISSN instead of ISBN
- [ops] Update website to use jQuery to v2.2.4, added Reactify plugin
- [ops] Converted bigquery to use docs
- [ops] Internal improvements to the resolver gateway and resolver microservice
- Data holdings and pipelines
- 37,583 more records, 605,305 more citations
- [ops] Our VMWare-based pipeline servers had to be restarted.
- [ops] Over the last week, 99.93% of queries returned successfully.
- Website and API
Development details
- Bumblebee (front-end/website) releases
- Export releases
- Resolver gateway releases
- Resolver service releases
- Tugboat releases
October 2019
- Development and data holdings updates as of October 1st:
- Website and API
- [new] Added option to transfer ownership of a library, accessible from the Manage Access tab in the library
- [new] In Application Settings, added the ability to set a default search form (Modern, Classic, Paper)
- [new] Added infrastructure endpoint to eventually support myADS settings imports
- [improved] If sidebars are hidden, requests to populate them are now blocked to improve load speed
- [improved] Library exports are now using the docs() syntax, to improve speed
- [improved] Added more flexibility for specifying BibTeX key format and max author settings for BibTeX and BibTeX ABS formats
- [improved] Improved scoring algorithm deployed; sort by score to use
- [fixed] Bug fixes to web interface: Classic search form now respects collections preferences set in Application Settings, fixed bug that caused the number of results to occasionally disappear on the results page, fixed bug for displaying special characters in the publication field on the abstract page
- [fixed] Fixed which field is being exported as the publisher field
- [ops] Add more info to logging requests
- [ops] Streamlined and added to Google Analytics timing logging
- [ops] Internal updates to builds and dependencies
- Data holdings and pipelines
- 53,878 more records, 613,711 more citations
- [fixed] Fixed citation_count field, some records had no value instead of a 0
- [fixed] Reviewed and fixed metadata parse issues for all bibcodes
- [fixed] Fixed publication data on PNAS records
- [fixed] Fixed 2019GeoJI records.
- [ops] Updated affiliation field for all bibcodes
- [ops] Over the last week, 99.99% of queries returned successfully.
- [ops] Fulltext pipeline XML extraction updated to BeautifulSoup4
- Website and API
Development details
- ADS Web Services releases
- Author affiliation releases
- Bumblebee (front-end/website) releases
- Export releases
- Graphics service releases
- Harbour service releases
- Resolver service releases
- Solr (search engine) releases
September 2019
- Development and data holdings updates as of September 1st:
- Website and API
- [new] Activated symbolic date math logic. Searches like entdate:[“NOW-1MONTH” TO NOW] will now work
- [new] Videos section added to help pages, including recordings of Office Hours talks
- [improved] Several improvements to Solr search engine scoring: improved the algorithm for choosing amongst synonyms, updated handling of multi-phrase synonyms, improved relevancy scoring, allow for multi-multi-valued affiliations (e.g. authors with multiple affiliations), improved handling of author accents with transliterations
- [improved] Added clarification to Help pages’ FAQ section about replacements for Classic’s “Get citation lists” and “Get reference lists” functions
- [fixed] Bug fixes to export service: better detection of math mode, limit the number of authors in MNRAS-style export
- [fixed] Fixed bug when there is a caret in the query string in object searches
- [fixed] Fixes to Solr search engine scoring: fixed NGC object search handling/tokenization, fixed year:xxxx-yyyy searches, fixed issue with constant scoring for position searches, fixed bugs affecting authors with multiple initials, scoring fix for first-author search using the caret (^) operator
- [ops] More info included with feedback form emails
- [ops] Better internal logging, including logging user ID with requests
- [ops] Better error handling for failed cone object searches
- [ops] Improved Solr warm-up, for performance
- Data holdings and pipelines
- 47,005 more records, 835,256 more citations
- [fixed] Fixed bug in search code that affected 0.5% of facet searches. Now, 99.97% of queries return now successfully.
- [fixed] The fulltext pipeline had inconsistent encoding issues that were fixed by detecting the encoding of a file and decoding it before parsing.
- [ops] Daily updates failed on two occasions, one due to central server room network issues and one from an abnormally large log file filling a disk.
- [ops] Updated 24469 ICRC records, 4309 arXiv records, 1114 Zenodo records, and 25 Minor Planet Bulletin records.
- [ops] Improved handling and internal reporting of fulltext pipeline errors.
- Website and API
Development details
- ADS Web Services releases
- Libraries releases
- Export releases
- Object service releases
- Solr (search engine) releases
- v63.1.0.59
- v63.1.0.58
- v63.1.0.57
- v63.1.0.56
- v63.1.0.55
- v63.1.0.54
- v63.1.0.53
- v63.1.0.52
- v63.1.0.51
- v63.1.0.50
- v63.1.0.49
- v63.1.0.48
- v63.1.0.47
- v63.1.0.46
- v63.1.0.45
- Solr (search engine) service releases
August 2019
- Development and data holdings updates as of August 1st:
- Website and API
- [new] Citation key in BibTeX exports is now configurable
- [new] Maximum number of authors to display in a BibTeX export is now configurable
- [new] Documentation: object search syntax added to search syntax help pages, new tutorial available for generating files for UI troubleshooting
- [new] New blog post on user-developed tools
- [improved] Updates to feedback form, including added links to correction forms
- [improved] Application settings page now auto-saves
- [improved] Documentation: overhaul of custom export format documentation
- [fixed] Fixed issue for Internet Explorer 11 users
- [fixed] Updated BibTeX export files to use .bib instead of .bbl extension
- [fixed] Fixed export menu ordering
- [fixed] Fixed table of contents bugs
- [fixed] Fixed library sorting bug
- [fixed] Fixed property logic in Classic form
- [fixed] Fixed issue with handling long author list in exports
- [fixed] Fixed bug for records with a certain EID format that occurred with some export formats
- [fixed] Updates to date/pubdate and bibstem fields in exports
- [fixed] Fixed AASTeX export format issue
- [fixed] Fixed indentation on custom export formats
- [fixed] No longer doing TeX manipulation of strings in math mode during export
- [fixed] Fixed several logging error messages
- [fixed] Fixed cone search functionality in object searches
- [ops] Now using https instead of http for calls to NED and SIMBAD
- [ops] Updated rate limiting for searches
- Data holdings and pipelines
- 45,499 more records, 582,817 more citations
- [ops] References were missing for at least 75 bibcodes. This was corrected by resending all reference data.
- [ops] Detected at least two bibcodes are missing the arxiv_class field. Correction to metadata has been requested.
- [ops] Updated our affiliation database with hundreds of new definitions and reprocessed all affiliation strings.
- Website and API
Development details
July 2019
- Development and data holdings updates as of July 1st:
- Website and API
- [new] Select desired articles and limit search results to the selected set using the new “limit to” button (visible after selecting one or more articles)
- [new] Search examples on Modern form are now clickable links
- [improved] Improved wording and functionality when using second-order operators from the Explore menu for a selected group of articles
- [improved] About menu includes link to What’s New page
- [fixed] Better error handling and improved performance issues
- [fixed] Improved client-side caching
- [fixed] Fixed sorting by normalized citations
- [fixed] Fixed sorting during export
- [fixed] Fixed issue to now allow results to open in new tab
- [ops] Improved session handling
- [ops] Increased rate limits for legitimate traffic
- Data holdings and pipelines
- 54,835 more records, 767,576 more citations
- [improved] Improved reliability of data ingest pipeline
- [improved] Updated solr records to use improved bibstem and institution fields
- [fixed] Changed default value for normalized citation count field to fix sorting issue
- [ops] Fixed publisher bibcode for a set of conference papers
- [ops] Deployed support for author/reviewer attributes
- [ops] Recovered from server room cooling failure
- [ops] Fixed links data for workshop
- Website and API
Development details
June 2019
- Development and data holdings updates as of June 1st:
- Website and API
- [new] Second order operators now available for a manually selected group of articles via the Explore menu
- [improved] Library set operations - improved: user experience, error handling, default library descriptions, tool tips
- [improved] Improved usage of reCAPTCHA
- [improved] Removed day from pubdate quick-field format
- [improved] Added IRSA data provider
- [improved] Updated classic form to allow hyphenated search terms
- [improved] Detect ctrl+click on links to help with Windows users
- [improved] Added warning messages in the Classic Search Translator for title and abstract search errors
- [fixed] Fixed routing issue that caused 404 pages to trap users
- [fixed] Fixed issue causing stuttered scrolling on iOS devices
- [fixed] Fixed associated papers widget to show properly
- [fixed] Quote author names by default in classic form
- [fixed] Fixed export output to remove extraneous characters
- [fixed] Fixed public library routing Issue, and update other links with same issue
- [fixed] Fixed library export control to respect selected sort
- [fixed] Fixed issue causing abstract citation list to have wrong title
- [fixed] Removed synonym replacement for object searches
- [ops] Added content-type for bigquery requests from several internal services
- Data holdings and pipelines
- 61,016 more bibcodes, 719,093 more citations
- [improved] Overnight arXiv records are now available sooner, due to code improvements
- [improved] Improved error handling for OCR errors in papers
- [improved] Improved generation of bibcodes when the page number overflows its field
- [improved] Improved quality of metrics data
- [new] In development: code to generate pages for web crawlers
- Website and API
Development details
- Author Affiliation releases
- Libraries releases
- Bumblebee (front-end/website) releases
- Export releases
- Object service releases
- Resolver service releases
- Solr (search engine) releases
- Solr service releases
- Tugboat (Classic Search Translator) releases
- Visualization service releases
May 2019
- Development and data holdings updates as of May 1st:
- Website and API
- [new] Implemented lazy loading of widgets to improve site performance
- [new] New feature: library set operations, available under Action button within library module
- [new] New search field: “inst” (institution) field is now available for users to search the set of curated affiliations, currently available from the left-side filters; this complements the existing “aff” (affiliation) field, which allows users to search the uncurated text of this field
- [improved] Additional export formats added to be more compatible with Classic-style export
- [improved] arXiv ID is now pushed with ORCID claims to improve record matching on the ORCID site
- [improved] Improvements to showing/hiding the sidebars
- [improved] Improved UX on fast connections
- [improved] arXiv ID added to abstract screens
- [fixed] Fix for default naming in library set operations
- [fixed] Fixed several bugs for exporting citations: fixed G author format, fixed journal name for macro matching, fixes to be more compatible with Classic-style export
- [fixed] Fixed several bugs in Classic query translator: fixed bugs in parsing bibstems to include/exclude, fixed bug when querying for a single author, fixed bug to ensure database selection is passed, cleaned up error messages
- [fixed] Fixed bug to speed site load
- [fixed] Fixed several ORCID bugs related to the ORCID login, claiming records with no abstract, claiming/updating records using an alternate bibcode, updating records from the ORCID profile screen, requiring user to log into ORCID again if ORCID login has expired
- [fixed] Fixes to the Classic and Paper forms
- [fixed] Fixes to library interface including who could view public libraries, fix for viewing large libraries in search results screen, fix for adding record to a library from the abstract screen
- [fixed] Numerous bug fixes in the user interface to improve user experience
- [fixed] Fixes to link handling and routing
- [fixed] Fixes to ensure compatibility with older browsers and for users who have Google blocked
- [ops] Fix to internal user account cleanup script
- [ops] Infrastructure to support forthcoming new feature: docs() operator, for performing operations on a selected group of articles or library
- [ops] Initial deployment of service to load static pages for abstracts to improve site speed; service still in development
- [ops] Internal build-related updates, updates to continuous integration, updates to unit testing infrastructure
- [ops] Changes in how errors from the Classic query translator are handled
- Data holdings and pipelines
- 51,795 more bibcodes, 799,237 more citations
- [improved] Complete records from arXiv papers are now searchable several hours earlier.
- [ops] Performance of our search engines continues to be monitored and improved.
- Website and API
Development details
- ADS Web Services releases
- Libraries releases
- Bumblebee (front-end/website) releases
- Export releases
- Solr (search engine) service releases
- Tugboat (Classic query translator) releases
- Turbobee releases
April 2019
- Development and data holdings updates as of April 1st:
- Website and API
- [fixed] Fixed error for users with no works on their ORCID profiles
- [operations] Updated “CXO” to “Chandra” as a data source name
- [operations] Updated expiration dates for access tokens
- Data holdings and pipelines
- 57,929 more bibcodes, 836,963 more citations
- [new] The augment affiliation pipeline was productized and has reprocessed millions of affiliation records
- [improved] The full text pipeline was improved to better handle text in appendices and text from specific publishers
- [improved] Production search engine performance has been improved
- [operations] We had some issues with a Solr search engine instance restarting; we are still investigating
- Website and API
Development details
March 2019
- Development and data holdings updates as of March 1st:
- Website and API
- [improved] Better handling of requests to API to improve speed
- [improved] Major back-end ORCID update, including many speed improvements, particularly for users with large profiles
- [improved] Added new CfA logo to footer, updated footer styling
- [improved] “Export” renamed to “Export Citation” on abstract page
- [improved] Added “entdate” field and “similar” operator to Quick Fields menu
- [fixed] Fixed issue where default database/collection was not always applied, even if set in preferences
- [fixed] Fixed handling if an ORCID login fails
- [fixed] Operators that require sorting by score are now sorting properly
- [fixed] Copying and pasting into the search box no longer triggers the autocomplete
- [fixed] Fixed export of accented characters
- [fixed] Fixed behavior of %U, which outputs the URL of the bibcode, in custom export
- [fixed] Year and month in BibTeX export are now wrapped in double quotes, per the BibTeX standard
- [fixed] Fixed line breaks in the author and editor fields in the BibTeX export to not wrap in the middle of a name
- Data holdings and pipelines
- 65,903 more bibcodes, 769,972 more citations
- [improved] We deployed improvements to our orcid pipeline and our master pipeline.
- [improved] We continued to productize the affiliation enhancement pipeline.
- [operations] Zendo based software citations ran in production mode.
- [operations] All pipelines ran without interruptions for the month.
- Website and API
Development details
February 2019
- Development and data holdings updates as of February 1st:
- Website and API
- [new] Set operations (union, intersection, difference, copy) available for libraries when using the API (not yet available in the browser).
- [fixed] Fixed how the custom export handles user-supplied LaTeX commands.
- [operations] Internal improvements to request handling.
- Data holdings and pipelines
- 32,886 more bibcodes, 527,614 more citations
- [new] Results of our affiliation enhancement project are becoming visible to users. We deployed improved affiliation data and faceted search support for several million bibcodes.
- [new] Our first software citations via Zenodo (bibstem:zndo) are available.
- [operations] Ingest pipelines was down for a day due to server room issues.