SciX Data Collections
Alberto Accomazzi & Edwin Henneken (SciX Team)
25 Aug 2025
In addition to its main high-level disciplinary collections (Astronomy, Earth Science, Physics, and General Science), the Science Explorer currently maintains a set of “data collections” to help scientists discover and analyze resources associated with research datasets. The SciX search engine implements a search by data collection via its data search field (e.g. data:Zenodo) or its data filter, available in the left bar of search results pages. The filter displays the names of repositories hosting datasets linked to the SciX records selected by the query (see fig. 1).
As can be seen from the list of datasets displayed in the filter, data collections are sets of records labeled with the name of the repository that is hosting related data products. The list includes well-known disciplinary repositories such as the ORNL DAAC, NOAA, GSFC; general-purpose ones such as Zenodo, GITHUB, and Figshare; and a generic entry (“DATASOURCE”) used as a label for data hosted by repositories that don’t appear on our list of known archives.
In addition to being able to select records in a data collections by using the proper filter, one can also use the corresponding search constraint via the data field, e.g. data:ORNL.DAAC will return all records that belong to the NASA’s ORNL.DAAC collection.
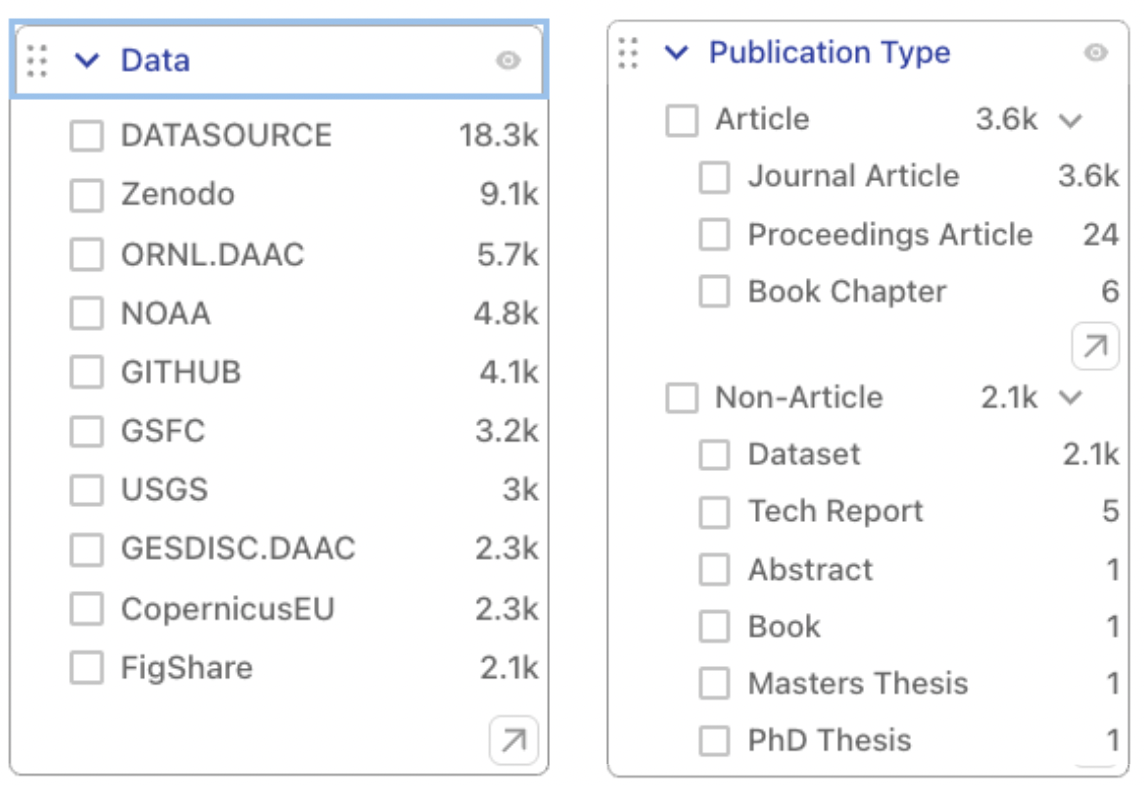 Figure 1: Left: Data collections currently available in SciX’s Earth science collection (`collection:earthscience`). Right: Publication types for records currently found in the ORNL DAAC data collection (`data:ORNL.DAAC`).
Figure 1: Left: Data collections currently available in SciX’s Earth science collection (`collection:earthscience`). Right: Publication types for records currently found in the ORNL DAAC data collection (`data:ORNL.DAAC`).
Contents
The records found in a given data collection consist of resources which either are datasets hosted by a particular repository or use data from a particular repository. The first category typically consists of high-level data products that are indexed in SciX. Examples of such records include ones found in the different NASA DAACs (original observations by NASA’s earth observing satellites) or the VizieR data products (machine readable datasets associated with astronomy articles), which have been indexed in the system to make them discoverable and citable. The second category includes data bibliographies which link articles to datasets hosted by the repositories. Examples include the SIMBAD and NED collections, which link articles to measurements of astronomical objects, and the collections from the astrophysics archives (MAST, Chandra, IRSA, HEASARC), which link papers to data products hosted by them.
In order to distinguish between records which correspond to a dataset from the records of papers that use the dataset, one can simply use the “Publication Type” filter to see the different documents available in the particular collection. As an example, figure 1 shows the documents found in the ORNL DAAC data collection.
Curation
All data collections in SciX are curated according to various criteria and various levels of effort. Historically, the collections associated with the data hosted by the astrophysics archives have been maintained by curators working at the different archives, and have relied on a meticulous analysis of the papers published in the scientific journals of interest to astronomers. (For more information on the process followed, please refer to this publication).
With the advent of electronic publishing and the adoption of FAIR principles, more and more publishers are requiring that software and data products be identified either through a formal citation, or as a mention in the scientific paper. This makes it possible for SciX to automate the process of identifying the use of datasets and attribute to them either a formal citation or a credit for its mention in the paper (more on this later). If the data product in question is indexed in SciX, proper links between the source paper and the target dataset are created. If the dataset is not indexed but the data product is available online, SciX will provide a link to it so that researchers can access it. It is important to remember that our ability to use text mining and machine learning to automate this process depends greatly on the availability of full-text content from publishers which collaborate with SciX.
In general, any given data collection may be composed by aggregating records which are curated by data managers collaborating with SciX, and records which are mined from the literature by the indexing pipelines implemented by SciX. As our full-text holdings in SciX increase and our ability to incorporate robust AI/ML methods in our pipelines improves, we expect to reduce the amount of human efforts needed to curate these collections long-term.
Citations and Credits
One distinctive feature of SciX is to track citations between research works. While this has traditionally meant providing links between papers based on the list of formal citations found in their bibliography, it has now made it possible to also track citations between a paper and a data product or software records. This information is exposed in SciX via the “Citations” tab available in the left menu for each record, as shown in figure 2.
However, thanks to our text mining efforts, we are now able to supplement this information with additional links between papers and datasets or software mined from the papers’ full-text (typically the so-called “data availability statement” sections). This provides an additional set of linkages between papers and data products mentioned in them which are named credits in SciX. This will become an additional impact metric that we will track for an increasingly larger number of research products such as data and software going forward.
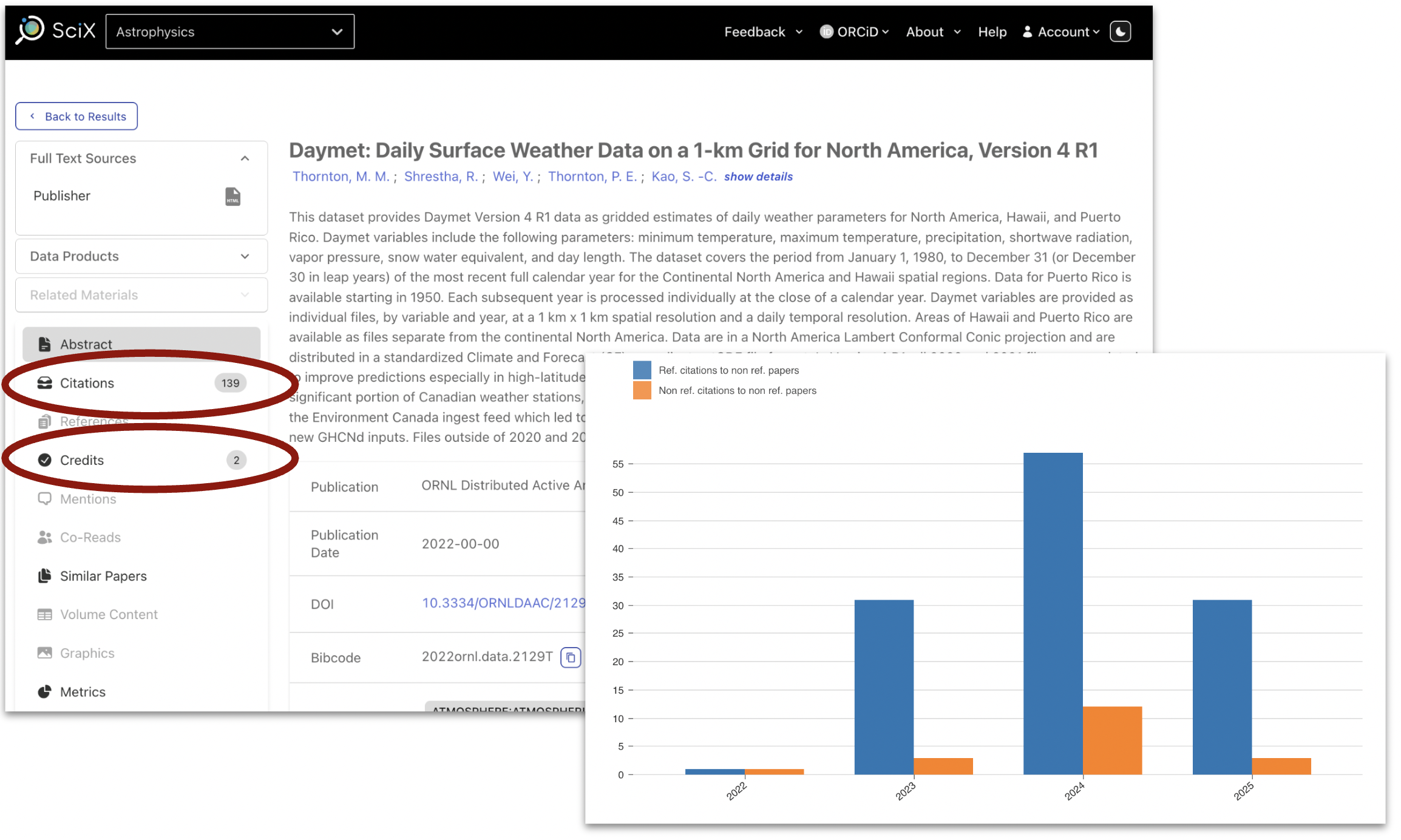 Figure 2: The SciX record for a dataset hosted by the ORNL DAAC. As of 8/25/2025, SciX has identified 139 citations and 2 credits from mentions for the dataset. Insert: the corresponding citation metrics for the record in question.
Figure 2: The SciX record for a dataset hosted by the ORNL DAAC. As of 8/25/2025, SciX has identified 139 citations and 2 credits from mentions for the dataset. Insert: the corresponding citation metrics for the record in question.
Concluding Remarks
Tracking the use of research data and software in the scientific literature is one of the primary goals of SciX. This not only helps reproducibility of scientific results, but it also allows greater discoverability of all the research artifacts involved: papers, software, and datasets. An additional benefit of enhancing the FAIRness of this content is the ability for researchers, data managers, and funders alike to evaluate the scientific impact of people, projects and institutions.
For more information on our efforts in capturing citations and credits to datasets and for practical examples of how to leverage SciX’s features further, please see our 2024 blog post by Edwin Henneken on SciX Data Linking and Indexing.
Questions or feedback? Contact us at adshelp@cfa.harvard.edu.