Second-Order Queries
We provide five second-order operators which modify the query results by performing second-order operations on the original query. Theese operators are database functions which form secondary queries based on attributes of the objects returned in an initial query; they can provide powerful methods to investigate complex, multipartite information graphs. To invoke the operators, enter the corresponding operator before your search terms (enclosing your search terms in parentheses) in the search box. The search terms enclosed by parentheses are considered the first-order query.
In addition to the basic information provided below, we have published a tutorial describing these operators in detail, both alone and in conjunction with other functions. It is intended for scientists and others who wish to make fuller use of the SciX database.
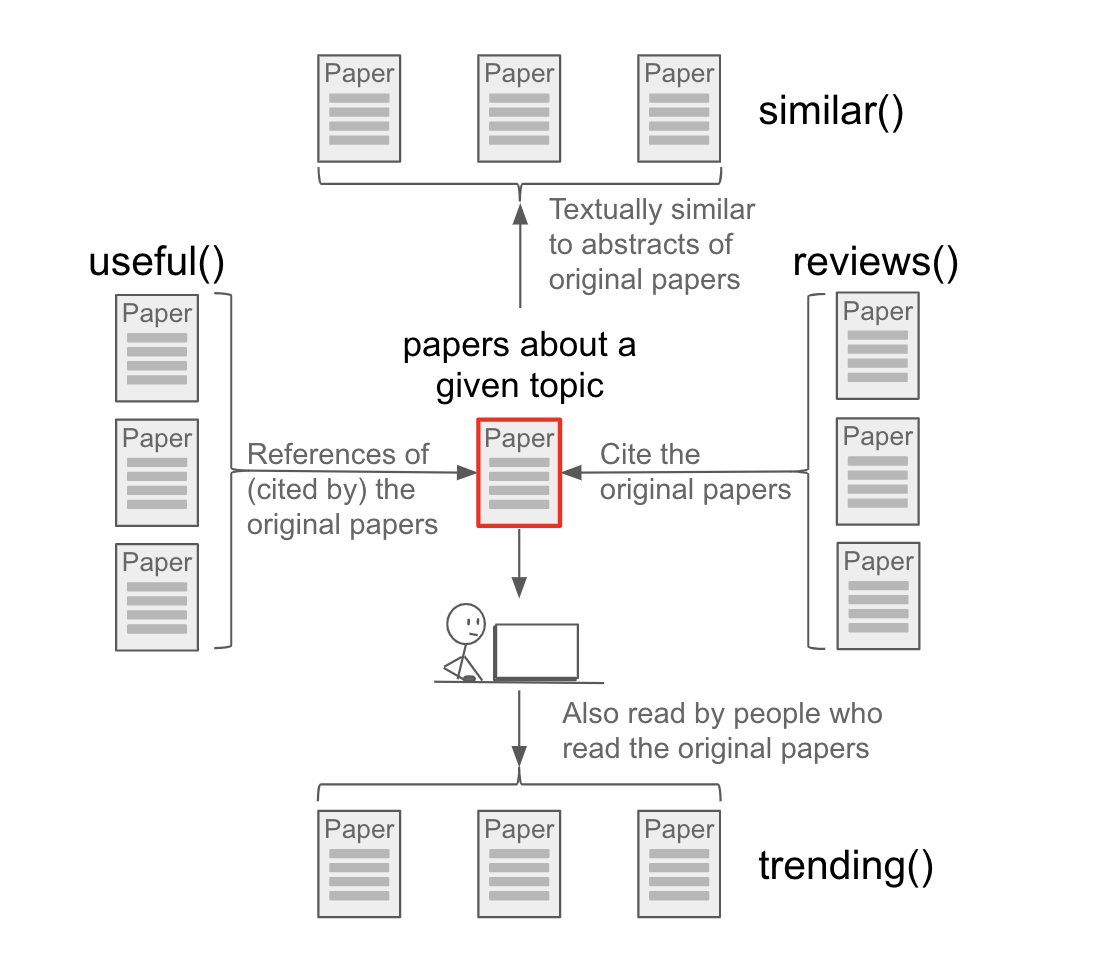
Similar - The similar operator takes the text of the abstracts of the papers in the first-order query, combines them into a single “document,” then ranks all the abstracts in ADS by their text-based similarity to this combined document, and returns the ranked list. The returned results exclude the articles returned by the first-order query. The documents returned are the most similar, as determined via text analysis, to the topic being researched, while excluding the original documents. For example:
similar(bibcode:2000A&AS..143...41K)
will return a ranked list of papers that are textually similar to the given paper, while excluding the given paper from the results.
The next example:
similar("weak lensing" -entdate:[NOW-7DAYS TO *]) entdate:[NOW-7DAYS TO *] bibstem:"arXiv"
will return a ranked list of recent arXiv papers that are textually similar to older papers about weak lensing. Note that since the similar operator excludes results returned by the first-order query, we here use separate date ranges in the first-order query and the outer query in order to force the queries to be disjoint.
Trending – The trending operator takes the lists of readers who read the papers in the first-order query, finds the lists of papers which each of them read, combines these lists, and returns the combined list, sorted by frequency of appearance. The documents returned are most read by users who read recent papers on the topic being researched; these are papers currently being read by people interested in this field. For example:
trending(exoplanets)
will return a ranked list of papers which are currently popular among the readers interested in exoplanets.
Useful – The useful operator takes the reference lists from the papers in the first-order query, combines them and returns this list, sorted by how frequently a referenced paper appears in the combined list. The documents returned are frequently cited by the most relevant papers on the topic being researched; these are studies which discuss methods and techniques useful to conduct research in this field. For example:
useful("galaxy surveys")
will return a ranked list of papers spanning a variety of topics useful to researchers interested in analyzing surveys of galaxies.
Reviews – The reviews operator takes the lists of articles which cited the papers in the first-order query, combines them, and returns this list sorted by how frequently a citing paper appears in the combined list. The documents returned cite the most relevant papers on the topic being researched; these are papers containing the most extensive reviews of the field. For example:
reviews("weak lensing")
will return a ranked list of papers featuring reviews of weak gravitational lensing and its cosmological implications.
TopN – returns the list of top N documents for a user defined query, where they are ordered by their default sort order or a user specified sort order. For example:
topn(100, database:astronomy, citation_count desc)
will return the top 100 most cited astronomy papers.
This next example uses the default sort order for the interior query, so no sort order needs to be specified:
trending(topn(10, reviews("weak lensing")))
This query returns papers currently being read by users who are interested in the field of weak lensing.